
















Optimizing query performance: The implementation of the OpenSearch index request cache
Speed and efficiency are essential for search users. OpenSearch achieves these through various mechanisms, one of the most important of which being the index request cache. This blog post describes how this cache is implemented and how it optimizes query performance.
What is the index request cache?
The index request cache is designed to accelerate search queries in OpenSearch by storing query results at the shard level, as shown in the following image.
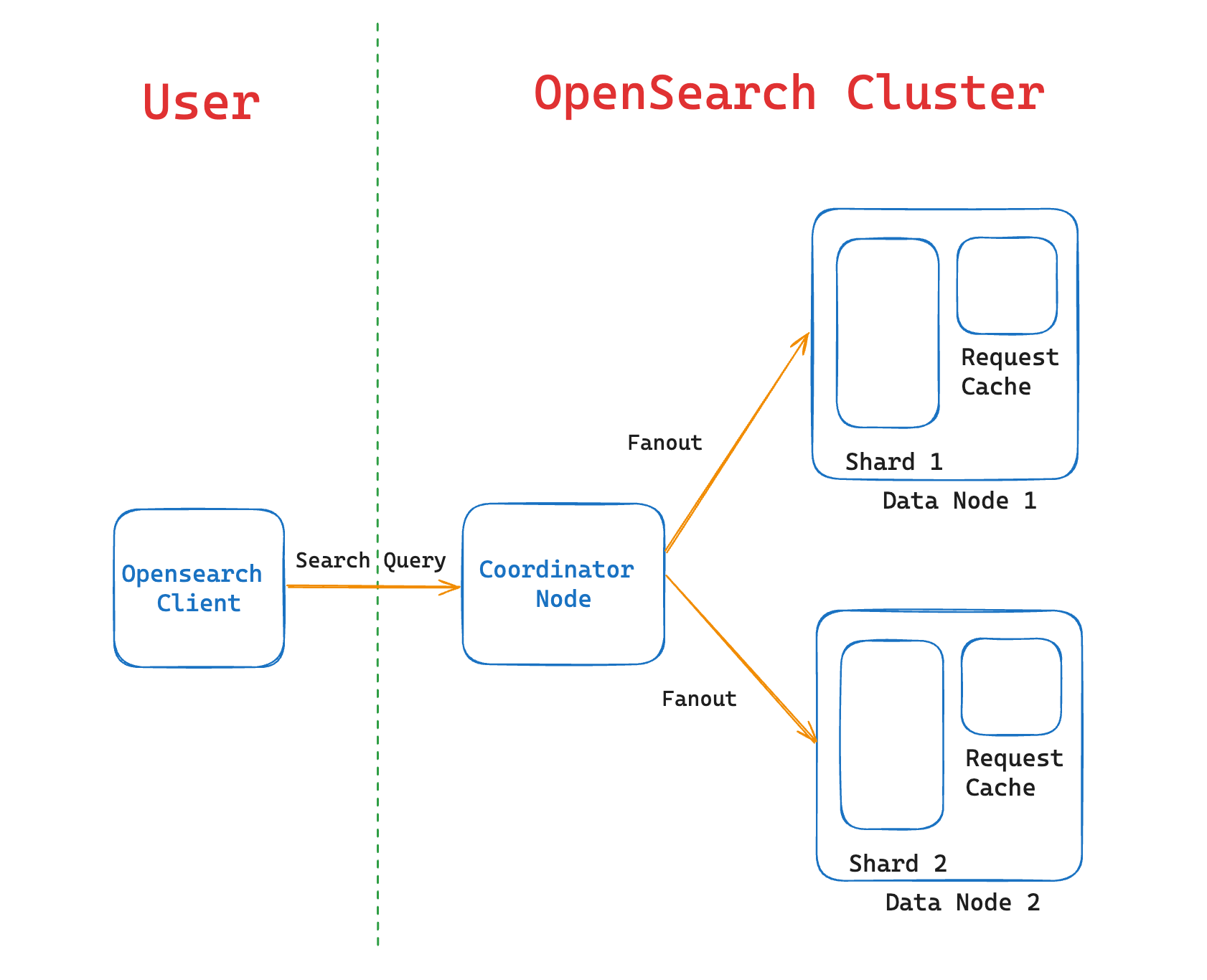
Caching frequently run queries reduces the need to re-execute the same query multiple times. This approach is particularly effective for queries targeting specific indexes or patterns, improving response times and overall system efficiency. The cache automatically clears entries when the data changes, ensuring that only up-to-date information is returned.
Caching policy
Not all search requests are eligible for caching in the index request cache. Search requests that specify size=0 are cached by default. These requests cache only metadata, such as the total number of results or hits.
The following requests are ineligible for caching:
- Non-deterministic requests: Searches involving functions, like
Math.random(), or relative times, such asnowornew Date(). - Scroll and Profile API requests
- DFS query then fetch requests: This search type depends on both index content and overridden statistics, leading to inaccurate scores when the statistics differ (for example, because of shard updates).
You can enable caching for individual search requests by setting the request_cache query parameter to true:
GET /students/_search?request_cache=true
{
"query": {
"match": {
"name": "doe john"
}
}
}
Understanding cache entries
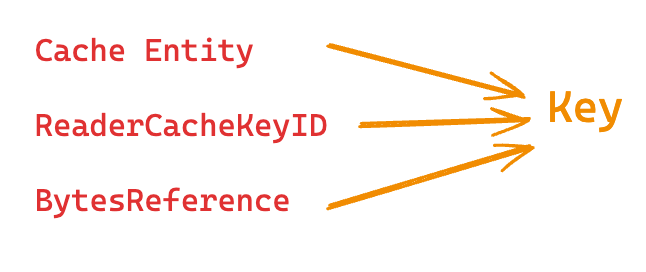
Each cache entry is a key-value pair consisting of Key → BytesReference.
A Key consists of three entities:
- CacheEntity: An IndexShardCacheEntity contains the IndexShard. This reference links the key to its shard.
- ReaderCacheKeyId: A unique identifier for the current state of the shard. This reference changes when the shard’s state changes (for example, after a document addition, deletion, update, or refresh).
- BytesReference: The actual search query, stored in byte format.
Together, these three components ensure that each key uniquely identifies a specific query targeting a particular shard, as shown in the following diagram. This process also verifies that the shard’s state is current, preventing retrieval of stale data.
Storing entries in the cache
Any cacheable query calls the getOrCompute method, which either fetches a precomputed value from the cache or stores the result in the cache after computation.
The following is the implementation of the getOrCompute method:
function getOrCompute(CacheEntity, DirectoryReader, cacheKey) {
// Step 1: Get the current state identifier of the shard
readerCacheKeyId = DirectoryReader.getDelegatingCacheKey().getId()
// Step 2: Create a unique key for the cache entry
key = new Key(CacheEntity, cacheKey, readerCacheKeyId)
// Step 3: Check if the result is already in the cache
value = cache.computeIfAbsent(key)
// Step 4: If the result was computed (not retrieved from the cache), register a cleanup listener
if (cacheLoader.isLoaded()) {
cleanupKey = new CleanupKey(CacheEntity, readerCacheKeyId)
OpenSearchDirectoryReader.addReaderCloseListener(DirectoryReader, cleanupKey)
}
// Step 5: Return the cached or computed result
return value
}
Cache invalidation
An IndexReader provides a point-in-time view of an index. Any operation that modifies the index’s contents creates a new IndexReader and closes the old one. Cache entries created by the old IndexReader then become stale and must be cleaned up.
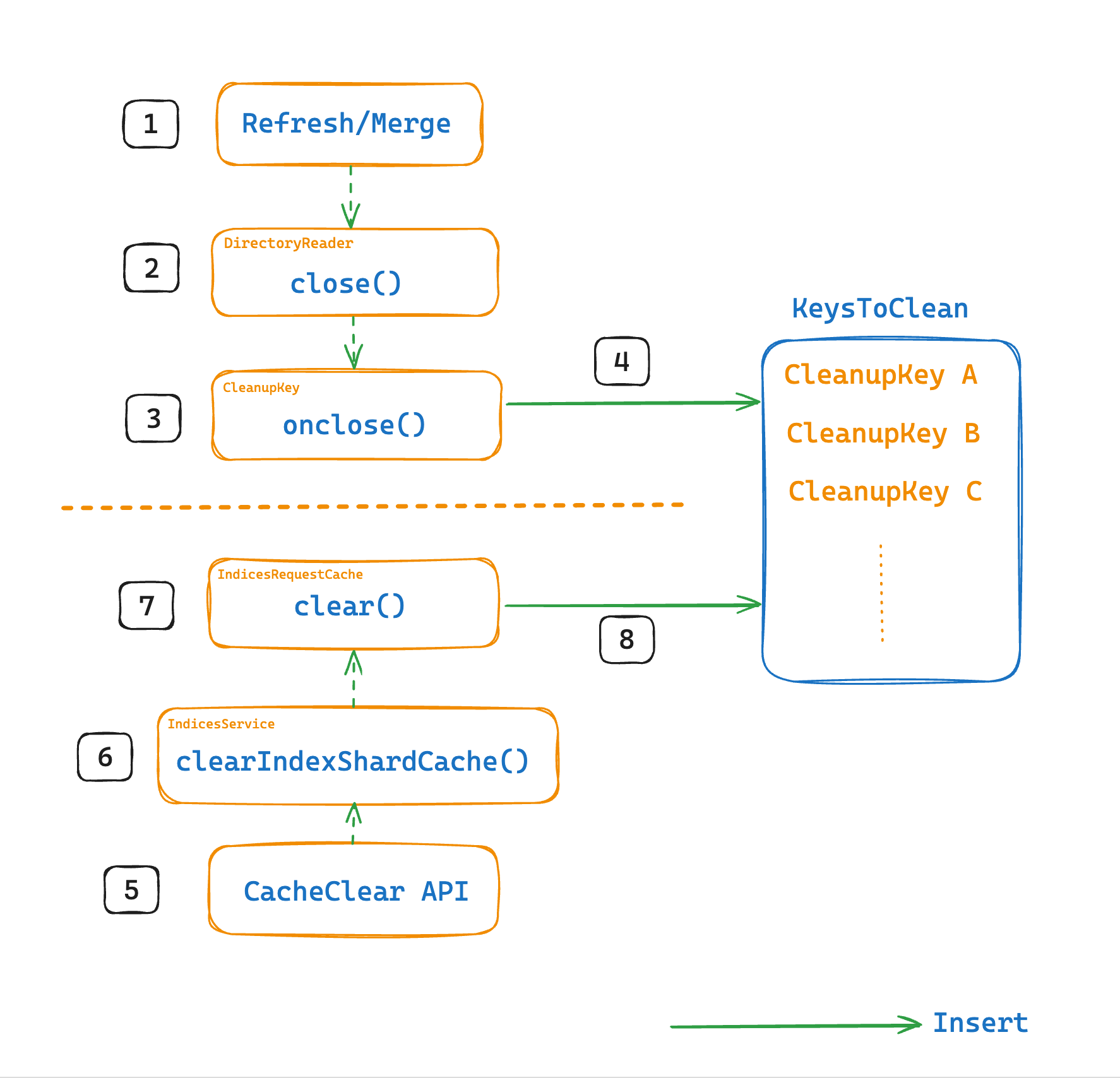
CleanupKey
A CleanupKey corresponds to a Key to be deleted. The relationship between them is shown in the following diagram.

When an IndexReader is closed, the corresponding CleanupKey is added to a set called KeysToClean.
BytesReference is not used by the CleanupKey because it represents the cached data itself, which is not needed to identify which entries should be cleaned up. The CleanupKey only identifies the entries to be removed and is not concerned with their contents.
A cache entry can become invalid because of the following operations:
- Refresh/merge: A
refreshormergeoperation creates a newIndexReader, thereby invalidating the cache entry. - Clear cache: A clear cache API operation invalidates all request cache entries for the specified index. You can call the Clear Cache API as follows:
POST /my-index/_cache/clear?request=true
Any operation that invalidates an IndexReader or explicitly clears the cache add a corresponding CleanupKey to a collection called KeysToClean, as shown in the following diagram.
Cache cleanup
Every minute, OpenSearch runs a background job called CacheCleaner on a separate thread. This job calls the cleanCache method, which iterates through all cache entries, maps each Key to a CleanupKey in KeysToClean, and removes the corresponding entries, as shown in the following diagram.
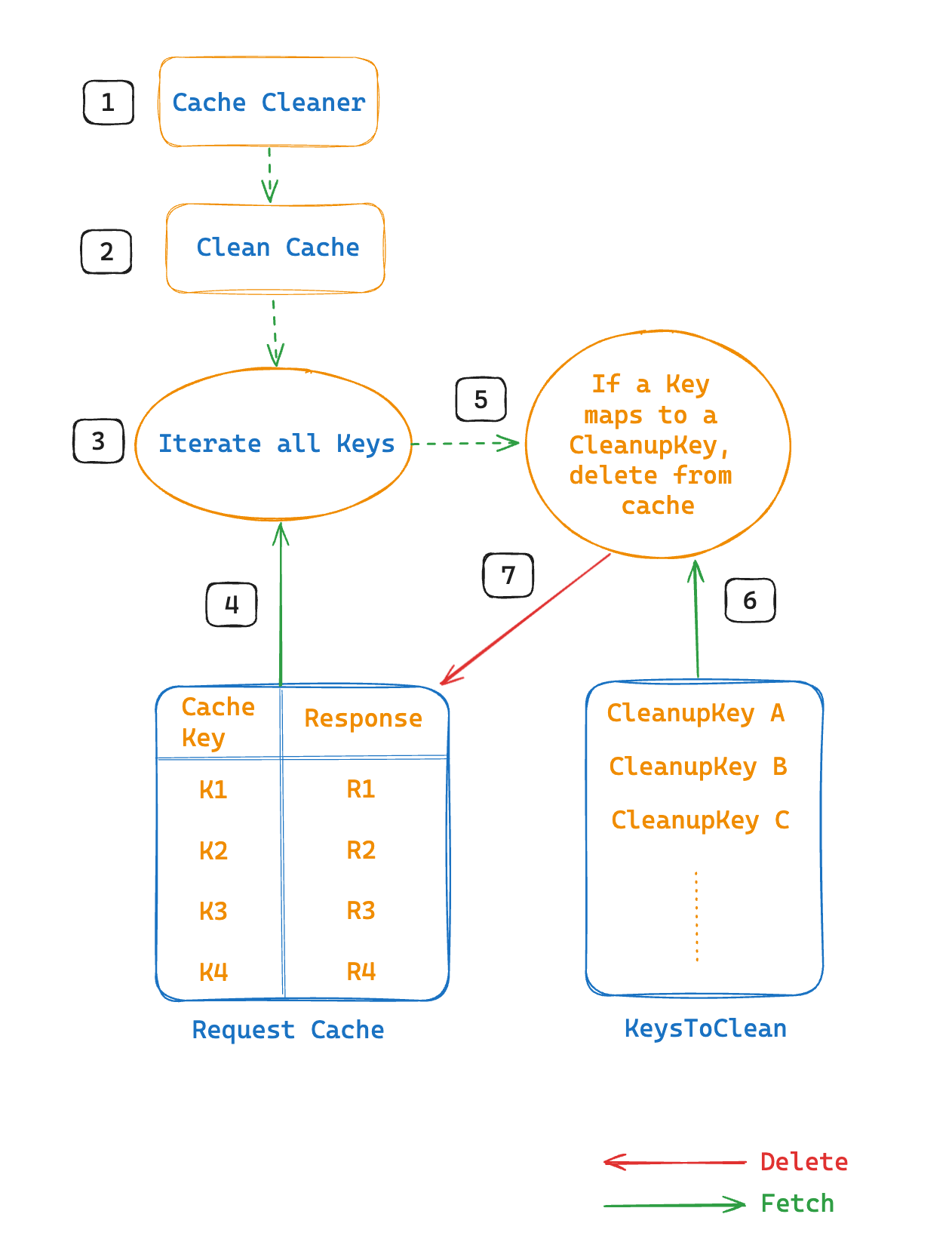
The following is the implementation of the cleanCache method:
function cleanCache() {
// Step 1: Initialize sets for keys to clean
currentKeysToClean = new Set()
currentFullClean = new Set()
// Step 2: Process the list of keys that need to be cleaned
for each cleanupKey in keysToClean {
keysToClean.remove(cleanupKey)
if (shard is closed or cacheClearAPI called) {
currentFullClean.add(cleanupKey.entity.getCacheIdentity())
} else {
currentKeysToClean.add(cleanupKey)
}
}
// Step 3: Process the cache and remove identified keys
for each key in cache.keys() {
if (currentFullClean.contains(key.entity.getCacheIdentity()) or
currentKeysToClean.contains(new CleanupKey(key.entity, key.readerCacheKey))) {
cache.remove(key)
}
}
// Step 4: Refresh the cache
cache.refresh()
}
Wrapping up
The index request cache plays a crucial role in ensuring the efficiency of OpenSearch. By understanding how it works, you can optimize performance and fine-tune your configurations with greater confidence.
The OpenSearch Project thrives on community contributions. If you have suggestions for improvement, consider contributing to the project. Your input can help shape the future of this search technology.



