
















Tiered caching in OpenSearch
For performance-intensive applications like OpenSearch, caching is an essential optimization. Caching stores data so that future requests can be served faster, improving query response times and application performance. OpenSearch uses two main cache types: a request cache and a query cache. Both are on-heap caches, meaning their size is determined by the amount of available heap memory on a node.
On-heap caching: A good start, but is it enough?
On-heap caching in OpenSearch provides a quick, simple, and efficient way to cache data locally on a node. It offers low-latency data retrieval and thereby provides significant performance gains. However, these advantages come with trade-offs, especially as the cache grows. When the cache size is close to capacity, on-heap caching may lead to performance challenges because of a high number of evictions and misses.
The size of an on-heap cache size is directly tied to the amount of heap memory available on a node, which is both finite and costly. This limitation creates a challenge when trying to store large datasets or manage numerous queries. When the cache reaches its capacity, older queries must often be evicted to make room for new ones. This frequent eviction can lead to cache churn, negatively impacting performance, because evicted queries may need to be recomputed later.
Is there a better way?
As discussed, on-heap caching has limitations when managing larger datasets. A more effective caching mechanism is tiered caching, which uses multiple cache layers, starting with on-heap caching and extending to a disk-based tier. This approach balances performance and capacity, allowing you to store larger datasets without consuming valuable heap memory.
In the past, using a disk for caching raised concerns because traditional spinning hard drives were slower. However, advancements in storage technology, like modern SSD and NVMe drives, now deliver much faster performance. Although disk access is still slower than memory, the speed gap has narrowed enough that the performance trade-off is minimal and often outweighed by the benefit of increased storage capacity.
How tiered caching works
Tiered caching combines multiple cache layers stacked by performance and size. For example, Tier 1 can be an on-heap cache, which is most performant but smaller in size. Tier 2 can be a disk-based cache, which is slower but offers significantly more storage. The following image shows a tiered caching model.
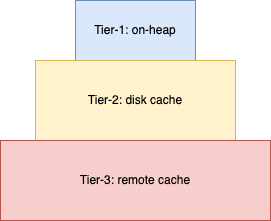
OpenSearch currently uses an on-heap tier and a disk tier in its tiered caching model. When an item is evicted from the on-heap cache, it’s moved to the disk cache. For each incoming query, OpenSearch first checks whether the data exists in either the on-heap or disk cache. If it’s found, the response is returned immediately. If not, the query is recomputed, and the result is stored in the on-heap cache. The following diagram depicts the caching algorithm.
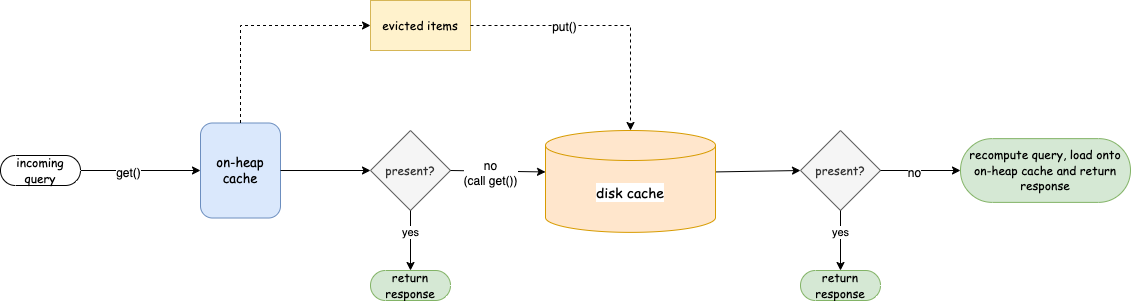
Currently, OpenSearch supports the tiered caching model only for the request cache. By default, the request cache uses the on-heap cache tier. The cache size is configurable and defaults to 1% of the heap memory on a node. You can enable tiered caching to add a disk-based cache tier, which stores larger datasets that don’t fit in memory. This offloads the on-heap cache, improving overall performance.
Tiered caching is also designed to be pluggable. You can seamlessly integrate different types of on-heap and disk cache implementations or libraries using tiered cache settings. For more information, see Tiered cache.
When to use tiered caching
Because tiered caching currently only applies to the request cache, it’s useful when the existing on-heap request cache isn’t large enough to store your datasets and you encounter frequent evictions. You can check request cache statistics using the GET /_nodes/stats/indices/request_cache endpoint to monitor evictions, hits, and misses. If you notice frequent evictions along with some hits, enabling tiered caching could provide a significant performance boost.
Tiered caching is especially beneficial in these situations:
- Your domain experiences many cache evictions and has repeated queries. You can confirm this by using request cache statistics.
- You’re working with log analytics or read-only indexes, in which data doesn’t change often, and you’re encountering frequent evictions.
By default, the request cache only stores aggregation query results. You can enable caching for specific requests by using the ?request_cache=true query parameter.
How to enable tiered caching
To enable tiered caching, you’ll need to configure node settings. This includes installing the disk cache plugin, enabling tiered caching, and adjusting other settings as needed. For detailed instructions, see the tiered cache documentation.
Performance results
This feature is currently experimental and isn’t recommended for production use. To assess its performance, we conducted several tests.
In our performance tests, we compared tiered caching with the default on-heap cache across various query types and cache hit ratios. We also measured different latency percentiles (p25, p50, p75, p90, and p99).
Cluster setup
- Instance type: c5.4xl
- Node count: 1
- Total heap size: 16 GB
- Default cache settings: On-heap cache size: 40 MB
- Tiered cache settings:
- On-heap cache size: 40 MB
- Disk cache size: 1 GB
We used the nyc_taxis workload in OpenSearch Benchmark but needed to add support for issuing statistically repeatable queries. The original benchmark always runs with caching disabled, which doesn’t allow for variation in query repetition. By adding this support, we could better simulate real-world use cases, test for a target cache hit ratio, and account for query repetition variability.
The workload consisted of a mix of queries categorized by their shard-level latencies:
- Expensive: >150 ms
- Medium: 10–150 ms
- Cheap: <10 ms
The following diagram presents the performance test results. The red vertical line denotes the baseline percentiles, where the default on-heap cache is enabled and tiered caching is disabled. We tested with 0%, 30%, and 70% query repeatability, corresponding to different cache hit ratios.
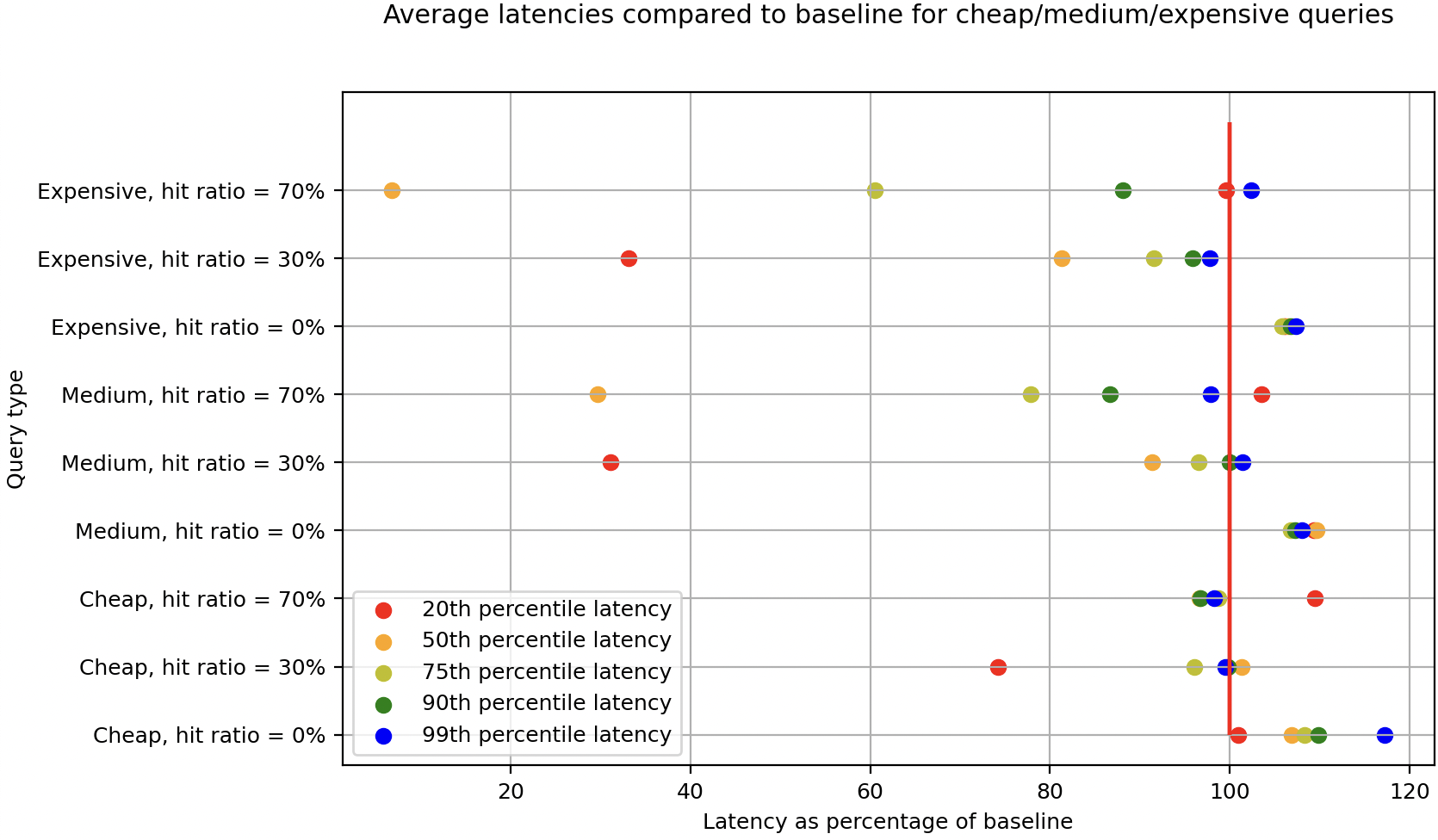
The initial results show that tiered caching performs well, especially with higher cache hit ratios and latencies lower than p75. The gains are particularly notable when running computationally expensive queries because tiered caching reduces the need to recompute them, fetching results directly from the cache instead.
What’s next?
While tiered caching is a promising feature, we’re actively working on further improvements. We’re currently exploring ways to make tiered caching more performant. Future enhancements may include promoting frequently accessed items from the disk cache to the on-heap cache, persisting disk cache data between restarts, and integrating tiered caching with other OpenSearch cache types, such as the query cache. You can follow our progress in this issue. We encourage you to try tiered caching in a non-production environment and to share your feedback to help improve this feature.




