
















Snapshot Operations in OpenSearch
In this post, we want to dive deep into snapshot operations in OpenSearch. Snapshots are backups of a cluster’s indexes and state. The state can include cluster settings, node information, index metadata, and shard allocation information. Snapshots are used to recover from failures, such as a red cluster, or to move data from one cluster to another without data loss. Remote searchable snapshots will enable users to restore a snapshot without downloading all the shards on the cluster nodes, requiring us to dive deep into the existing snapshot operations within OpenSearch.
This post will help you understand the fundamentals of snapshot operations. If you enjoy this topic and want to put your knowledge into practice, please consider contributing to remote searchable snapshots.
What snapshot operations can I perform on my cluster?
You can perform the following snapshot operations on a cluster:
- Creating a snapshot: This operation creates a snapshot within a repository, backing up the cluster settings and index data.
- Deleting a snapshot: This operation deletes unwanted versions of a snapshot from a repository.
- Restoring a snapshot: This operation restores a snapshot within a repository in the event of a failure or cluster migration to bring the cluster back to the same state as when the snapshot was created.
The SnapshotsService is responsible for creating and deleting snapshots, whereas the RestoreService is responsible for restoring snapshots. We will cover these operations in detail in the following sections. A key thing to note is that snapshots are incremental in nature, meaning that they only store data that has changed since the last successful snapshot. Refer to Take and restore snapshots for more information.
How are snapshots stored?
A snapshot is a backup taken from a running OpenSearch cluster and stored within a repository.
What is a repository?
A Repository acts as an interface on top of an underlying storage system and provides higher-level APIs for working with snapshots. The repository interface is part of the plugin feature of OpenSearch. Out of the box, OpenSearch comes with three repository implementations—Amazon Simple Storage Service (Amazon S3), Azure Blob Storage, and Google Cloud Storage—that can be optionally enabled in your installation. External developers can also provide their own implementation of a repository if none of the existing implementations fit their use case.
The abstract class BlobStoreRepository provides the base implementation of a repository, which implements all common snapshot management operations. The default shared file system repository is implemented by the FsRepository, whereas the repositories for other types of storage systems are provided as plugins.
Internally, a BlobStoreRepository uses a BlobStore, a wrapper on top of a BlobContainer, that provides additional operations such as retrieving stats on the store. Further, the BlobContainer interface is an abstraction on top of the underlying storage systems (such as a shared file system and the other plugin-based implementations) for managing blob entries, where each blob entry is a named group of bytes. The concrete implementations of the BlobContainer interface define the CRUD operations on blob entries. For instance, FsRepository uses the FsBlobContainer as the file-system-based implementation of the BlobContainer. For other storage systems, specific repository plugins provide the underlying implementations, such as S3BlobContainer, GoogleCloudStorageBlobContainer, AzureBlobContainer, and HdfsBlobContainer.
The following diagram depicts the relationships between Repository, BlobStore, and BlobContainer.
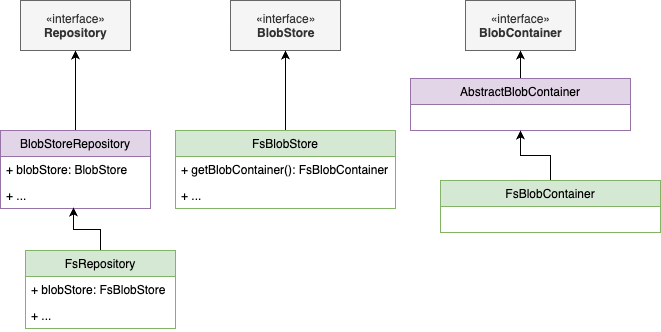
What is the structure of a repository?
A repository can store multiple snapshots, which can contain a single index or multiple indexes. At the low level, the RepositoryData object holds the list of all snapshots as well as the mapping of the index name to the repository IndexId. For each shard i in a given index, its path in the blob store is root/indices/${index-snapshot-uuid}/${i}. The following diagram shows the directory structure of the blob store (For more information, see Javadocs).
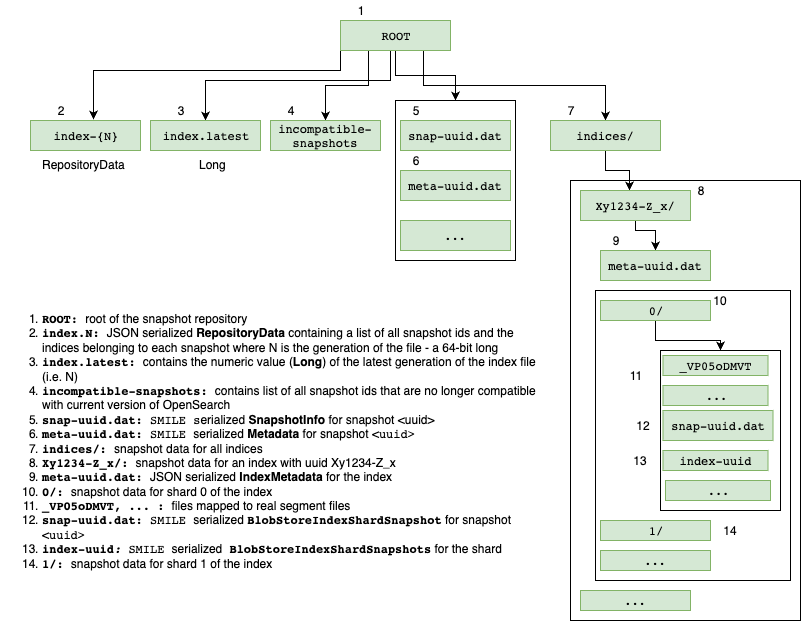
How does snapshot creation work?
Clients can create snapshots by performing a PUT operation on the _snapshot API (For more on the snapshot creation API, see Take snapshots). The SnapshotService.createSnapshot method is called to create a new snapshot. Only one snapshot creation process can be running at a given time.
How do the nodes coordinate for a snapshot operation?
The ClusterState object holds the information about the current cluster state.
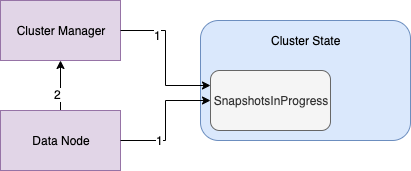
There are two communication channels for snapshots between the cluster manager and all other nodes:
- The cluster manager updates the
ClusterStateobject by adding, removing, or altering the contents of its custom entrySnapshotsInProgress. All nodes consume the state of theSnapshotInProgressand start or terminate the relevant shard snapshot tasks accordingly. - Nodes executing shard snapshot tasks report either success or failure of their snapshot tasks by submitting an
UpdateIndexShardSnapshotStatusRequestto the cluster manager node, which updates the snapshot’s entry in theClusterStateobject accordingly.
The following image depicts the interaction between the cluster manager node, the data nodes, and the ClusterState object described above.
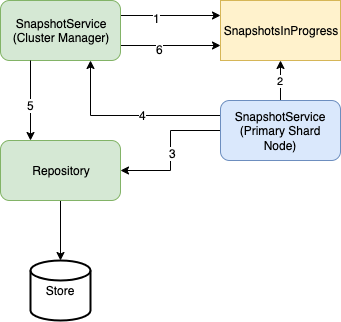
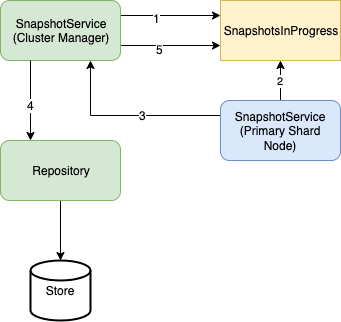
Flow of events for snapshot creation
The following image depicts the flow of events for snapshot creation. The numbers in the image correspond to the steps within the flow outlined below.
-
The
SnapshotServiceon the cluster manager node determines the node allocation of primary shards for all indexes that are part of the snapshot request. It then creates aSnapshotsInProgress.Entrywith theSTARTEDstate. Each snapshotEntryhas a map ofShardIdtoShardSnapshotStatusto keep track of the nodes and the shards associated with the snapshot. Each shard’s status (enumShardState) is set to one of the following:INIT– This is the initial state for all shards that have a healthy primary node.WAITING– Primary is initializing at this point.MISSING– Primary for a shard is unassigned.
SnapshotsInProgress is the container for the snapshot metadata that is part of the ClusterState object, hence this is updated by the cluster manager node using a ClusterStateUpdateTask.
- The primary node receives a ClusterChangedEvent and then executes the snapshot process for the shard with an
INITstate. - The primary nodes write the the shard’s data files to the snapshot’s repository.
- Once it finishes, the node sends an
UpdateIndexShardSnapshotStatusRequestto the cluster manager with a signal indicating the status of the snapshot process. The cluster manager then updates the state of the shard to one of the following:SUCCESS– The snapshot of the shard was successful.FAILED– Either the shard’s primary has been relocated after the entry was created or the snapshot process on the primary node failed.
- The cluster manager node then updates the entry for the snapshot to
SUCCESSif all the primary shards’ snapshots were in a completed state (SUCCESS,FAILED, orMISSING). It ends the snapshot process by writing all the metadata to the repository. - Finally, the cluster manager node removes the
SnapshotsInProgress.Entryfrom theClusterStateobject, indicating the end of the snapshot creation process.
Both the cluster manager and the data nodes can read from and write to a blob store. All metadata related to a snapshot’s scope and health is written by the cluster manager node only. Data nodes can only write the blobs for shards they hold as primary. The nodes write the primary shard’s segment files to the repository as well as metadata about all the segment files that the repository stores for the shard.
What happens on the primary data node for snapshot creation?
In the shard’s primary data node, the BlobStoreRepository.snapshotShard method is executed. The method performs the following steps:
- The method starts by taking a Lucene
IndexCommitobject and retrieving all file names related to the particular commit. - Then the method gets the
BlobStoreIndexShardSnapshotsobject, which contains information about all the snapshots in the repository for the assigned primary shard on the current data node. - After retrieving data from the
IndexCommitand the repository, the method compares the files inIndexCommitand existing files in the blob store to determine the new segment files to write. - The method then proceeds to build a new
BlobStoreIndexShardSnapshotthat contains a list of all the files referenced by the snapshot as well as some metadata about the snapshot. For each segment file, the method writes the referenced file to the blob store with a unique UUID whose mapping to the real segment file is in theBlobStoreIndexShardSnapshot. - The method then writes the
BlobStoreIndexShardSnapshotdata that contains the details of all files in the snapshot. - Finally, it writes the updated shard metadata
BlobStoreIndexShardSnapshots.
How is the snapshot metadata updated within the repository?
After all primaries have finished writing the necessary segment files to the blob store, the cluster manager node finalizes the snapshot by invoking Repository.finalizeSnapshot.
This method executes the following actions in order:
- First, the method writes a blob containing the cluster metadata to the root of the blob store repository at
/meta-${snapshot-uuid}.dat. - Then the method writes the metadata for each index to a blob in that index’s directory at
/indices/${index-snapshot-uuid}/meta-${snapshot-uuid}.dat. - The method then writes the
SnapshotInfoblob for the given snapshot to the key/snap-${snapshot-uuid}.datdirectly under the repository root. - Finally, the method writes an updated
RepositoryDatablob containing the new snapshot.
How are snapshots deleted?
Deletion of a snapshot involves either deleting it from the repository or terminating (if in progress) and subsequently deleting it from the repository. To delete it from the repository, clients can perform a DELETE operation on the _snapshot API.
Terminating snapshots
Terminating a snapshot starts by updating the state of the snapshot’s SnapshotsInProgress.Entry to ABORTED. Then, the following steps are performed:
- The termination of a snapshot begins when the snapshot’s state changes to
ABORTEDin theClusterStateobject by the cluster manager node. - This change in the
ClusterStateobject is then picked up by theSnapshotShardsServiceon all nodes. - Those nodes that are assigned a shard snapshot action terminate the process and notify the cluster manager. If the shard snapshot action was completed or in the
FINALIZEstate when the termination was registered by theSnapshotShardsService, then the shard’s state is reported to the cluster manager asSUCCESS. Otherwise, it is reported asFAILED. - Once all the shards’ statuses are reported to the cluster manager, the
SnapshotsServiceon the cluster manager finishes the snapshot process and updates the metadata in the repository. - Finally, the
SnapshotsServiceon the cluster manager removes theSnapshotsInProgress.Entryfrom the cluster state.
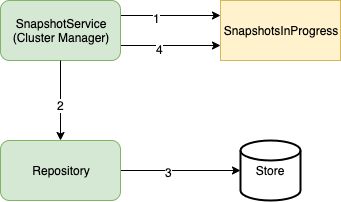
The following image depicts the interaction between the cluster manager, the repository, the data nodes, and the cluster state. The numbers in the image correspond to the steps described above.
Deleting a snapshot
Snapshot deletion is executed exclusively on the cluster manager node. To delete a snapshot, the following steps are performed:
- Assuming there are no entries in the
ClusterState’sSnapshotsInProgress, deleting a snapshot starts with theSnapshotsServicecreating an entry for deleting the snapshot in theClusterState’sSnapshotDeletionsInProgress. - Once the
ClusterStatecontains the deletion entry inSnapshotDeletionsInProgress, theSnapshotsServiceinvokesRepository.deleteSnapshotsfor the given snapshot. - The
Repositorythen removes files associated with the snapshot from the repository store and updates its metadata to reflect the deletion of the snapshot. - After the deletion of the snapshot’s data from the repository finishes, the
SnapshotsServicesubmits an update toClusterStateto remove the deletion’s entry inSnapshotDeletionsInProgress, which concludes the process of deleting the snapshot.
The following image depicts the interaction between the cluster manager, the repository, and the cluster state. The numbers in the image correspond to the steps described above.
How is the snapshot metadata updated within the repository?
In the cluster manager node, BlobStoreRepository.deleteSnapshots is executed.
This method executes the following actions in order:
- First, the method fetches the current
RepositoryDatafrom the latestindex-Nblob in the repository data. - Then, for each index referenced by the snapshot, the method performs the following:
- Deletes the snapshot’s
IndexMetadataat/indices/{index-snapshot-uuid}/meta-{snapshot-uuid}. - Iterates through all shard directories
/indices/{index-snapshot-uuid}/{i}and performs the following:- Removes the
BlobStoreIndexShardSnapshotblob at/indices/{index-snapshot-uuid}/{i}/snap-{snapshot-uud}.dat. - Lists all blobs in the shard path
/indices/{index-snapshot-uuid}and builds a newBlobStoreIndexShardSnapshotsfrom the remainingBlobStoreIndexShardSnapshotblobs in the shard. Afterwards, writes it to the next shard generation blob at/indices/{index-snapshot-uuid}/{i}/index-{uuid}(The shard’s generation is retrieved from the map of shard generations in theRepositoryDatain the rootindex-{N}blob of the repository). - Collects all segment blobs (identified by the data blob prefix __) in the shard directory that are not referenced by the new
BlobStoreIndexShardSnapshotsthat was written in the previous step and the previousindex-{uuid}blob so that it can be deleted at the end of the snapshot deletion process.
- Removes the
- The method then writes an updated
RepositoryDatablob where the deleted snapshot is removed and the repository generations that changed for the shards affected by the deletion are updated. - Then the method deletes the global metadata blob
meta-{snapshot-uuid}.datstored directly under the repository root for the snapshot as well as theSnapshotInfoblob at/snap-{snapshot-uuid}.dat. - Finally, the method deletes all the blobs with no references, which were collected when updating the shard directories, and removes any index folders or blobs under the repository root that are not referenced by the new
RepositoryDatawritten in the previous step.
- Deletes the snapshot’s
What happens when I restore a snapshot?
The RestoreService.restoreSnapshot method is used for restoring a snapshot from the repository. This method is executed when the clients call the _restore API under a particular snapshot to be restored. The following steps describe the snapshot restore operation:
- The service ensures the existence of the snapshot within the repository. It further ensures the ability to restore the snapshot by performing version checks against the snapshot metadata.
-
If the above checks succeed, the service reads additional information about the snapshot and the related metadata for the indexes within the snapshot. It also filters the requested indexes and performs any rename operation based on the request properties.
The next steps use the cluster state update task (
submitStateUpdateTask) to perform further restore operations. - For each index from
Step 2, the service performs the following steps:- It checks to ensure the snapshot being restored is not currently undergoing a delete operation. Otherwise, it fails with
ConcurrentSnapshotExecutionException. RestoreServiceensures that the index is currently either closed or does not exist, in which case it is restored as a new index or throws theSnapshotRestoreException.- Then, the
RestoreServicevalidates that the number of primary shards and replica shards for the index can be served by the current cluster setup. - Finally, the service adds the new routing and metadata entries once the above pre-checks have succeeded for the particular index.
- It checks to ensure the snapshot being restored is not currently undergoing a delete operation. Otherwise, it fails with
- After creating all the necessary structures for routing, metadata, and the shards, the
RestoreServicecreates aRestoreInProgress.Entry, which is added to the cluster state to keep track of the snapshot restore. This entry also hosts the individual shard states, which can be one of the following:INITSTARTEDSUCCESSFAILED
The shards are recovered using the
IndexShard.restoreFromRespository, where each shard goes through the above states to be restored from the repository to the assigned node. TheRestoreInProgress.Entryhas a corresponding overall state that is calculated using the individual shard states. - Eventually, the request is routed to
AllocationService, which takes care of allocating the unassigned shards and starting the shard recovery process. - During the shard recovery process, an observer instance of
RestoreInProgressUpdateris utilized to keep track of the shard states, which helps update the overall progress of snapshot restore. The observer instance contains the logic used to update the shard restore status within theRestoreInProgress.Entrybased on the current shard recovery status. - Finally, once the restore operations for all of the shards are complete, the overall status of
RestoreInProgress.Entryis updated to reflect aSUCCESSorFAILUREstatus. After this update,RestoreServicecallscleanupRestoreState, which removes theRestoreInProgress.Entryfrom the cluster state, concluding the restore process.
How can I contribute?
We are currently working on searchable snapshots, which involves working directly with the snapshot restore process and the repository interfaces. If you’d like to contribute, the following issues would be a great place to start:
- https://github.com/opensearch-project/OpenSearch/issues/2578
- https://github.com/opensearch-project/OpenSearch/issues/3895
- https://github.com/opensearch-project/OpenSearch/issues/2919


