
















Shard Indexing Backpressure in OpenSearch
In this post we wish to dive into the Shard Indexing Backpressure feature which got launched with OpenSearch 1.2.0 and how it can improve cluster reliability. The Indexing APIs in OpenSearch such as _bulk allows you to write data in the cluster, which is distributed across multiple shards, on multiple data nodes. However, at times indexing requests may suffer performance degradation due to a number of reasons including non-optimal cluster configuration, shard strategy, traffic spikes, available node resources and more. These issues are further exacerbated for larger multi-node cluster and indices with many shards. All of these could cause out-of-memory errors, long garbage collection (GC) pauses, and reduced throughput, affecting the overall availability of data nodes in addition to degrading performance. This in turn would impact the node’s ability to perform useful work. In addition, these node drop events could cascade due to a lack of effective backpressure which puts the entire cluster at risk.
Indexing Backpressure offers a real-time solution to address such issues, particularly for multi-node clusters with large data sets that have high throughput requirements. Indexing backpressure offers selective load-shedding of indexing requests when performance thresholds are exceeded. For example, in the case of too many stuck requests or request in the cluster running too long, indexing backpressure would kick in. This not only protects clusters from these types of cascading failures, but also ensures that the cluster can continue to perform as expected by only isolating the impacted paths. By tracking real-time performance on per shard basis in the background and evaluating them against dynamic thresholds, Indexing Backpressure applies appropriate in-time rejections decision at the shard-request level whenever a shard or a node suffers a duress situation affecting its ability to keep up with the other shards/nodes in the cluster. This prevents wide failures while also guaranteeing fairness in request execution.
What is Shard Indexing Backpressure protection and why is it important?
OpenSearch provides few control mechanisms today to prevent a data node meltdown for bulk indexing requests. These are essentially achieved by queue rejections, circuit breakers, and node-level memory limits for indexing traffic. However, these gating mechanisms are all static and reactive.
- Thread pool queue sizes are static in nature and do not change dynamically in real time. Every incoming request in the queue consumes resources differently.
- Circuit Breakers can track real-time memory utilization but most of them apply blanket level rejections without any fairness or identifying resources required for the requests.
- Node level Indexing Pressure limit framework is designed to reject overwhelming indexing requests based on some pre-defined static limits on nodes. It is similar to the blanket level rejections offered by circuit breakers.
Therefore, there is a need for smarter rejection mechanism at a granular level i.e. per shard request. This should help identify the underlying reason (slow indexing requests or stuck indexing tasks) for a performance breach in a cluster. Once the issue is detected, there is a need for an effective propagation of backpressure, transferring the load from the overwhelmed node to other nodes that are still healthy. Thus the healthy nodes are capable of taking smarter backoff and short circuit decisions while processing these requests.
How this feature solves the problem
Shard Level Indexing Backpressure introduces dynamic rejections of indexing requests when there are too many stuck or slow requests in the cluster, breaching key performance thresholds. This prevents the nodes in cluster to run into cascading effects of failures under arising due to:
- Performance Degradation – Indexing performance for a shard starts to indicate slowness overtime, such as due to configuration changes, resource contention, or poison-pill requests.
- Slow Nodes – Entire data node starts to slowdown due to degraded hardware such as disk, network volumes, or software bugs such as thread-pool blocks, mutex locks.
- Stuck Requests (Blackhole) - Requests get stuck indefinitely and takes forever to responds back due to a slow downstream node. However the upstream node continues to accept requests faster than they are being processed.
- Surge in traffic – Sudden surge or spike in the traffic to a leading quick build up across the nodes.
- Skewness in shard distribution – Improper distribution of shards leading to hot spots, bottlenecks, affecting the overall performance.
Below are some of the key features offered by the shard level indexing backpressure, which helps address the above scenarios:
- Granular tracking of indexing tasks performance, at every Shard level, for each Node role i.e. coordinator, primary and replica.
- Fair and Selective rejections by discarding the requests intended only for problematic path touching impacted indices or shards, while still allowing other requests to continue without any downtime.
- Rejections thresholds are governed by combination of configurable parameters (such as memory limits on node) and dynamic parameters (such as latency increase, throughput degradation).
- Node level and Shard level indexing pressure statistics are exposed to users through stats API.
- Control knobs to tune the key performance thresholds which governs the rejection decisions, to address any specific cluster requirements.
- Control knobs to run the feature either in Shadow-Mode or Enforced-Mode. Shadow-mode is a dry-run mode where only rejection breakdown metrics are published while no actual rejections are performed.
Step-by-step walk through
Shard level indexing backpressure focuses on dynamically assigning memory quota from the total memory pool to each shard based on its operational needs (i.e. the incoming workloads). A combination of shard level memory utilization and throughput enables OpenSearch to decide whether it should process a request. This also prevents other nodes in the cluster from running into cascading failures due to the performance degradation caused by slow node, stuck tasks, resource intensive requests, traffic surge, skewed shard allocation, etc. Shard level indexing backpressure depends on primary and secondary parameters to make decisions.
Primary Parameters
Primary parameters, are leading indicators for node duress and are governed through soft limits. We have two such primary parameters:
- Shard memory limit breach: The shard memory limit is breached if the allocated shard level memory limit is exceeded and there is a need to increase the allocation. At any given point the memory distribution algorithm will try to maintain that the current memory utilization of shard approximately 85% of the assigned shard memory. If the occupancy goes beyond 95%, this parameter is assumed to be breached.
- Node memory limit breach: The node memory limit is breached if the total allocated node level memory limit for indexing requests is exceeded. At any point the current memory utilization at the node level goes beyond 70% of total assigned node memory for indexing work, this parameter is assumed to be breached.
Breach of primary parameters reflect no actual rejections yet, but triggers an evaluation of the secondary signals.
Secondary Parameters
These parameters are based on granular, shard level performance such as request throughput and successful completion of requests. While these shard states are updated with every request, they are evaluated only when the primary parameters are breached. We have introduced two secondary parameters:
- Throughput: The framework tracks request latency per unit byte at the shard level and any substantial decrease in the shard throughput against its historic performance is considered a degradation.
- Successful Request: The framework also tracks successful indexing requests at the shard level and signals if there are large number of pending requests. This is used to detect memory build-ups due to stuck requests proactively and invoke the required backpressure.
Indexing backpressure takes effect when one of the primary parameters and secondary parameters’ thresholds are breached on the node. This results in rejection of new incoming requests/tasks for the affected shards on the node.
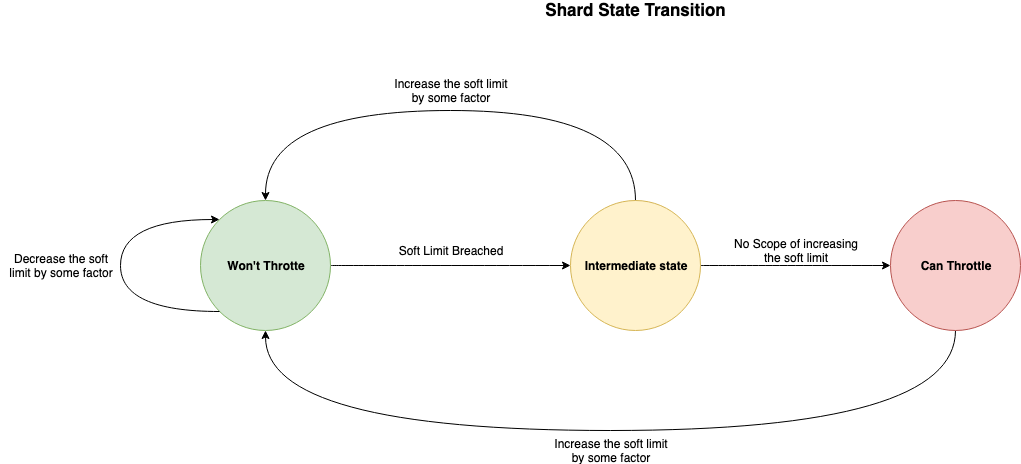
The mechanism used by indexing backpressure is fair. The selective rejections of requests are intended only for problematic index or shard, while still allowing others to continue. Below is the shard state transition diagram which covers these scenarios.
Stats API For Shard Indexing Backpressure
The performance and rejection statistics collected by the framework are exposed through REST APIs for users to have added visibility.
GET /_nodes/_local/stats/shard_indexing_pressure- Returns the Node level stats for indexing request rejections.
GET /_nodes/stats/shard_indexing_pressure- Returns the shard level breakup of indexing stats and rejections for every node. This only includes the hot shards (i.e. shards which have active writes currently going on them).
GET /_nodes/_local/stats/shard_indexing_pressure?include_all- Returns the Shards level breakup of indexing stats and rejections for every node. This includes all the shards, which either have active writes or had recent writes on them.
GET /_nodes/_local/stats/shard_indexing_pressure?top- Returns the top level aggregated indexing stats on rejections. Here the per shard statistics are not provided.
Sample response
{
"_nodes": {
"total": 1,
"successful": 1,
"failed": 0
},
"cluster_name": "runTask",
"nodes": {
"q3e1dQjFSqyPSLAgpyQlfw": {
"timestamp": 1613072111162,
"name": "runTask-0",
"transport_address": "127.0.0.1:9300",
"host": "127.0.0.1",
"ip": "127.0.0.1:9300",
"roles": [
"data",
"ingest",
"master",
"remote_cluster_client"
],
"attributes": {
"testattr": "test"
},
"shard_indexing_pressure": {
"stats": {
"[index_name][0]": {
"memory": {
"current": {
"coordinating_in_bytes": 0,
"primary_in_bytes": 0,
"replica_in_bytes": 0
},
"total": {
"coordinating_in_bytes": 299,
"primary_in_bytes": 299,
"replica_in_bytes": 0
}
},
"rejection": {
"coordinating": {
"coordinating_rejections": 0,
"breakup": {
"node_limits": 0,
"no_successful_request_limits": 0,
"throughput_degradation_limits": 0
}
},
"primary": {
"primary_rejections": 0,
"breakup": {
"node_limits": 0,
"no_successful_request_limits": 0,
"throughput_degradation_limits": 0
}
},
"replica": {
"replica_rejections": 0,
"breakup": {
"node_limits": 0,
"no_successful_request_limits": 0,
"throughput_degradation_limits": 0
}
}
},
"last_successful_timestamp": {
"coordinating_last_successful_request_timestamp_in_millis": 1613072107990,
"primary_last_successful_request_timestamp_in_millis": 0,
"replica_last_successful_request_timestamp_in_millis": 0
},
"indexing": {
"coordinating_time_in_millis": 96,
"coordinating_count": 1,
"primary_time_in_millis": 0,
"primary_count": 0,
"replica_time_in_millis": 0,
"replica_count": 0
},
"memory_allocation": {
"current": {
"current_coordinating_and_primary_bytes": 0,
"current_replica_bytes": 0
},
"limit": {
"current_coordinating_and_primary_limits_in_bytes": 51897,
"current_replica_limits_in_bytes": 77845
}
}
}
},
"total_rejections_breakup": {
"node_limits": 0,
"no_successful_request_limits": 0,
"throughput_degradation_limits": 0
},
"enabled": true,
"enforced" : true
}
}
}
}
How do I contribute to the feature?
If you have any feedback/suggestions on new topics please don’t hesitate to open issues or post to the forums. If you’d like to contribute, a great place to start would be the links below.
Meta Issue and Related PRs :
- https://github.com/opensearch-project/OpenSearch/issues/478
- https://github.com/opensearch-project/OpenSearch/pull/1336



