
















Semantic Search with OpenSearch: Architecture options and Benchmarks
Unlike traditional lexical search algorithms such as BM25, which only take keywords into account, semantic search improves search relevance by understanding the context and semantic meaning of search terms and context. In general, semantic search has two key elements: 1. Embedding generation: A machine learning (ML) model, usually a deep neural network model (for example, TAS-B) is used to generate embeddings for both search terms and content; 2. k-NN: Searches return results based on embedding proximity using a vector search algorithm like k-nearest neighbors (k-NN).
OpenSearch introduced the k-NN plugin to support vector search in 2019. However, users were left to manage embedding generation outside of OpenSearch. This changed with OpenSearch 2.9, when the new Neural Search plugin was released (available as an experimental feature in 2.4). The Neural Search plugin enables the integration of ML models into your search workloads. During ingestion and search, the plugin uses the ML model to transform text into vectors. Then it performs vector-based search using k-NN and returns semantically similar text-based search results.
The addition of the vector transformation to the search process does come with a cost. It involves making inferences using deep neural network (DNN) language models, such as TAS-B. And the inferences of these DNN models are usually RAM and CPU heavy. If not set up correctly, it can result in resource consumption pressure and impact the health of your cluster. In the rest of this post, we’ll introduce several different ways of configuring OpenSearch clusters for semantic search, explain in detail how each approach works, and present a set of benchmarks to help you choose one to fit your own use case.
Terms
Before we discuss the options, here are the definitions of some terms we’ll use throughout this post:
- Data node: Where OpenSearch data is stored. A data node manages a cluster’s search and indexing tasks and is the primary coordinator of an OpenSearch cluster.
- ML node: OpenSearch introduced ML nodes in 2.3. An ML node is dedicated to ML-related tasks, such as inference for language models. You can follow these instructions to set up a dedicated ML node.
- ML connector: Introduced with ML extensibility in 2.9, an ML connector allows you to connect your preferred inference service (for example, Amazon SageMaker) to OpenSearch. Once created, an ML connector can be used to build an ML model, which is registered just like a local model.
- Local/remote inference: With the newly introduced ML connector, OpenSearch allows ML inference to be hosted either locally on data or ML nodes; or remotely on public inference services.
Architecture options
OpenSearch provides multiple options for enabling semantic search: 1. Local inference on data nodes, 2. Local inference on ML nodes, 3. Remote inference on data nodes, and 4. Remote inference on ML nodes.
Option 1: Local inference on data nodes
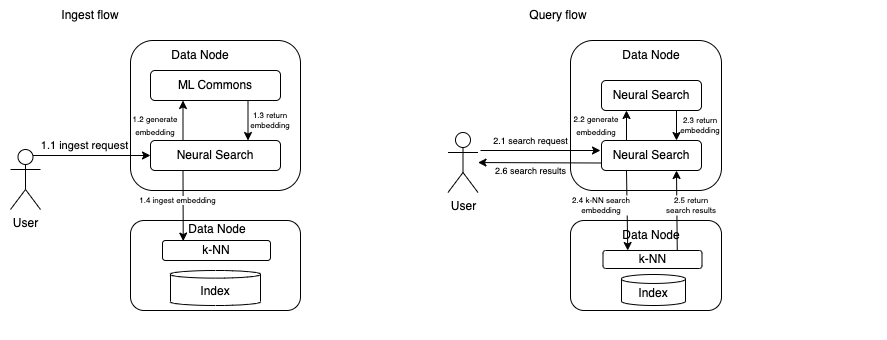
With this option, both the Neural Search and ML Commons plugins reside on data nodes, just as any other plugin. Language models are loaded onto local data nodes, and inference is also executed locally.
Ingest flow: As illustrated in Figure 1, the Neural Search plugin receives ingestion requests through the ingestion pipeline. It sends the text blob to ML Commons to generate embeddings. ML Commons runs the inference locally and returns the generated embeddings. Neural Search then ingests the generated embeddings into a k-NN index.
Query flow: For query requests, the Neural Search plugin also sends the query to ML Commons, which will inference locally and return an embedding. Upon receiving the embedding, Neural Search will create a vector search request and send it to the k-NN plugin, which will execute the query and return a list of document IDs. These document IDs will then be returned to the user.
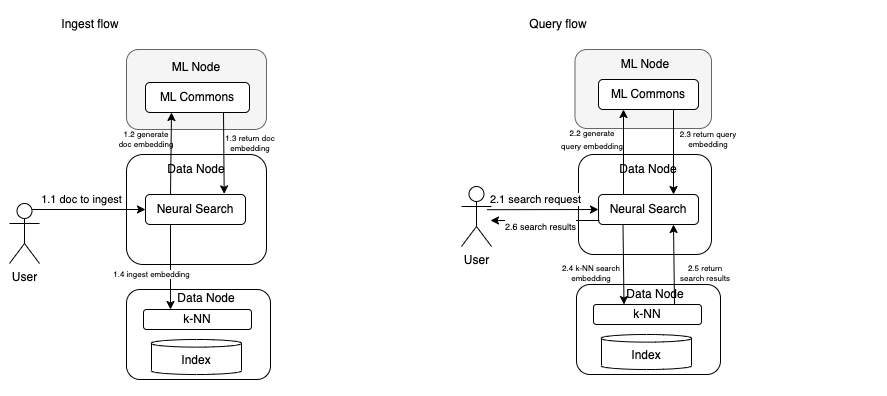
Option 2: Local inference on ML nodes
With this option, dedicated ML nodes are set up to perform all ML-related tasks, including inference for language models. Everything else is identical to option 1. In both the ingestion and query flows, the inference request to generate embeddings will now be sent to the ML Commons plugin, which resides on a dedicated ML node instead of on a data node, as shown in following figure:
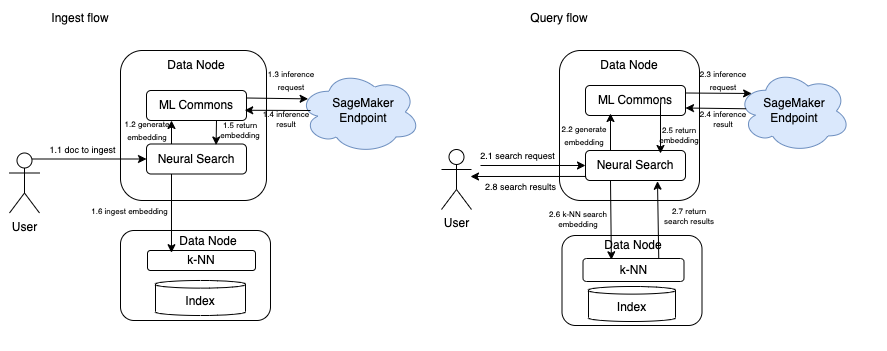
Option 3: Remote inference on data nodes
This option was introduced in OpenSearch 2.9 with the ML extensibility feature. With this option, you use the ML connector to integrate with a remote server (outside of OpenSearch) for model inference (for example, SageMaker). Again, everything else is identical to option 1, except the inference requests are now forwarded by ML Commons from data nodes to the remote SageMaker endpoint through an ML connector, as shown in following figure:
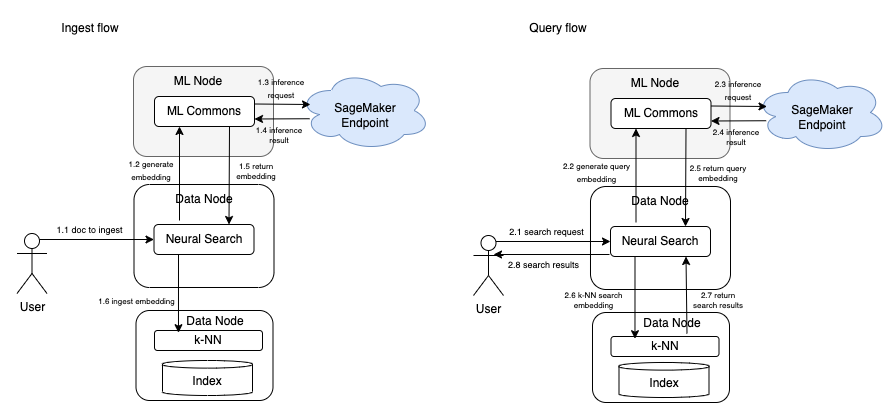
Option 4: Remote inference on ML nodes
This option is a combination of options 2 and 3. It still uses remote inference from SageMaker but also uses a dedicated ML node to host ML Commons, as shown in following figure:
Each of the four options presents some pros and cons:
- Option 1 is the default out-of-the-box option, it requires the least amount of setup configuration, and the inference requests are organically distributed by OpenSearch’s request routing. But running ML models on data nodes could potentially affect other data node tasks, such as querying and ingestion.
- Option 2 manages all ML tasks with dedicated ML nodes. The benefit of this option is that it decouples the ML tasks from the rest of the cluster, improving the reliability of the cluster. But this also adds an extra network hop to ML nodes, which increases inference latency.
- Option 3 leverages an existing inference service, such as SageMaker. The remote connection will introduce extra network latency, but it also provides the benefit of offloading resource-intensive tasks to a dedicated inference server, which improves the reliability of the cluster and offers more model serving flexibility.
- Option 4 adds dedicated ML nodes on top of remote inference. Similarly to option 2, the dedicated ML node manages all ML requests, which further separates the ML workload from the rest of the cluster. But this comes with the cost of the ML node. Also, because the heavy lifting of the ML workload happens outside of the cluster, the ML node utilization could be low with this option.
Benchmarking
To better understand the ingestion/query performance difference between these options, we designed a series of benchmarking tests. The following are our results and observations.
Experiment setup
- Dataset: We used MS MARCO as the primary dataset for benchmarking. MS MARCO is a collection of datasets focused on deep learning in search. MS MARCO has 12M documents, with an average length of 1,500 words, and is approximately 100 GB in size. Also note that we have truncation set up in models to only use the first 128 tokens of each document in our experiments.
- Model: We chose sentence-transformers/all-MiniLM-L6-v2 from a list of pretrained models supported by OpenSearch.
- All pretrained models support truncation/padding to control the input length; we set both at 128.
- Cluster configuration:
- Node type: M5.xlarge (4 core, 16 GB RAM)
- To ensure an apples-to-apples comparison, we configured all cluster options to use the same type and number of nodes in order to keep the cost similar:
- Option 1: Local inference on data nodes: 2 data nodes, 1 ML node
- Option 2: Local inference on ML nodes: 3 data nodes
- Option 3: Remote inference on data nodes: 2 data nodes, 1 SageMaker node
- Option 4: Remote inference on ML nodes: 1 data node, 1 ML node, 1 SageMaker node
- Benchmarking tool: We used OpenSearch Benchmark to generate traffic and collect results.
Experiment 1: Ingestion
Ingestion setup
| Configuration | Value |
|---|---|
| Number of clients | 8 |
| Bulk size | 200 |
| Document count | 1M |
| Local model truncation | 128 |
| SageMaker model truncation | 128 |
| Local model padding | 128 |
| SageMaker model padding | 128 |
| Dataset | MSCARCO |
Experiment 1: Results
| Case | Mean throughput (doc/s) | Inference p90 (ms/doc) | SageMaker inference p90 (ms/req) | SageMaker overhead p90 (ms/req) | e2e latency p90 (ms/bulk) |
|---|---|---|---|---|---|
| Option 1: Local inference on data nodes (3 data nodes) | 213.13 | 72.46 | N/A | N/A | 8944.53 |
| Option 2: Local inference on ML nodes (2 data nodes + 1 ML node) | 72.76 | 67.79 | N/A | N/A | 25936.7 |
| Option 3: Remote inference on data nodes (2 data nodes + 1 remote ML node) | 94.41 | 101.9 | 97 | 3.5 | 17455.9 |
| Option 4: Remote inference on ML nodes (1 data node + 1 local ML node + 1 remote ML node) | 79.79 | 60.37 | 54.8 | 3.5 | 21714.6 |
Experiment 1: Observations
- Option 1 provides much higher throughput than the other options. This is probably because ML models were deployed to all three data nodes, while the other options have only one dedicated ML node performing inference work. Note that we didn’t perform other tasks during the experiment, so all the nodes are dedicated to ingestion. This might not be the case in a real-world scenario. When the cluster multitasks, the ML inference workload may impact other tasks and cluster health.
- Comparing options 2 and 3, we can see that even though option 2 has lower inference latency, its throughput is much lower than with option 3, which has a remote ML node. This could be because the SageMaker node is built and optimized solely for inference, while the local ML node still runs the OpenSearch stack and is not optimized for an inference workload.
- Remote inference added some trivial overhead (3.5 ms, SageMaker overhead). We ran our tests on a public network; testing run on a virtual private cloud (VPC)-based network might yield slightly different results, but they are unlikely to be significant.
Experiment 2: Query
Query setup
| Configuration | Value |
|---|---|
| Number of clients | 50 |
| Document count | 500k |
| Local model truncation | 128 |
| SageMaker model truncation | 128 |
| Local model padding | 128 |
| SageMaker model padding | 128 |
| Dataset | MSCARCO |
Experiment 2: Results
| Case | Mean throughput (query/s) | Inference p90 (ms/query) | SageMaker inference p90 (ms/req) | SageMaker overhead p90 (ms/req) | e2e latency p90 (ms/query) |
|---|---|---|---|---|---|
| Option 1: Local inference on data nodes (3 data nodes) | 128.49 | 37.6 | N/A | N/A | 82.6 |
| Option 2: Local inference on ML nodes (2 data nodes + 1 ML node) | 141.5 | 29.5 | N/A | N/A | 72.9 |
| Option 3: Remote inference on data nodes (2 data nodes + remote ML node) | 162.19 | 26.4 | 21.5 | 4.9 | 72.5 |
| Option 4: Remote inference on ML nodes (1 data node + 1 local ML node + remote ML node) | 136.2 | 26.6 | 21.6 | 5 | 76.65 |
Experiment 2: Observations
- Inference latency is much lower than in the ingestion experiment (~30 ms compared to 60–100 ms). This is primarily because query terms are usually much shorter than documents.
- Externally hosted models outperformed local models on inference tasks by about 10%, even considering the network overhead.
- Unlike with ingestion, inference latency is a considerable part of end-to-end query latency. So the configuration that has the lowest latency achieves higher throughput and lower end-to-end latency.
- The remote model with a dedicated ML node ranked lowest in throughput, which could be because all remote requests have to pass through the single ML node instead of through multiple data nodes, as in the other configurations.
Conclusion/Recommendations
In this blog post, we provided multiple options for configuring your OpenSearch cluster for semantic search, including local/remote inference and dedicated ML nodes. You can choose between these options to optimize costs and benefits based on your desired outcome. Based on our benchmarking results and observations, we recommend the following:
- Remotely connected models separate ML workloads from the OpenSearch cluster, with only a small amount of extra latency. This option also provides flexibility in terms of the amount of computation power used for making inferences (for example, leveraging SageMaker GPU instances). This is our recommended option for any production-oriented systems.
- Local inference works out of the box on existing clusters without any additional resources. You can use this option to quickly set up a development environment or build PoCs. Because the heavy ML workload could potentially affect cluster query and search performance, we don’t recommend this option for production systems. If you do have to use local inference for your production systems, we strongly recommend to use dedicated ML nodes to separate ML workload from the rest of you cluster.
- Dedicated ML nodes helps improve query latency for local models (by taking over all ML-related tasks from data nodes), but they don’t help much with remote inference because the heavy lifting is performed outside of the OpenSearch cluster. Also, because ML nodes don’t manage any tasks not related to ML, adding an ML node won’t improve query or ingestion throughput.


