
















Improved durability in OpenSearch with remote-backed storage
We are excited to announce remote-backed storage, a new feature that enables request-level durability with remote storage options like Amazon Simple Storage Service (Amazon S3), Oracle Cloud Infrastructure Object Storage, Azure Blob Storage, and Google Cloud Storage. This was introduced as an experimental feature in OpenSearch 2.3 and is now generally available in OpenSearch 2.10. With this feature, users can achieve a recovery point objective (RPO) of zero and leverage the same durability properties of the configured remote store. In this blog post, we dive deep into architecture, benefits, trade-offs, and planned future enhancements.
Overview
Today, data indexed in an OpenSearch cluster is stored on a local disk. To achieve data durability, that is, to ensure that indexed operations are not lost in the event of infrastructure failure, users build complex mechanisms to retain and re-ingest data. Alternatively, they rely on snapshots that do not offer request-level durability or add more replicas, which require additional compute resources. Remote-backed storage addresses these concerns by providing a native solution.
Architecture
Core concepts
- Translog: The transaction log (translog) contains data that is indexed successfully but yet to be committed. Each successful indexing operation creates an entry in the translog, which is a write-ahead transaction log.
- Segment: Lucene segments are created from the indexed operations in a periodic manner by the OpenSearch process.
With remote-backed storage, in addition to storing data on a local disk, all the ingested data is stored in the configured remote store. OpenSearch keeps committed data as segments, and uncommitted data is added to the translog. To ensure consistency, the same semantics are used while storing the data in the remote store. The data in the local translog is backed up to the remote translog store with each indexing operation. Whenever new segments are created as part of refresh/flush/merge, the new segments are uploaded to the remote segment store.
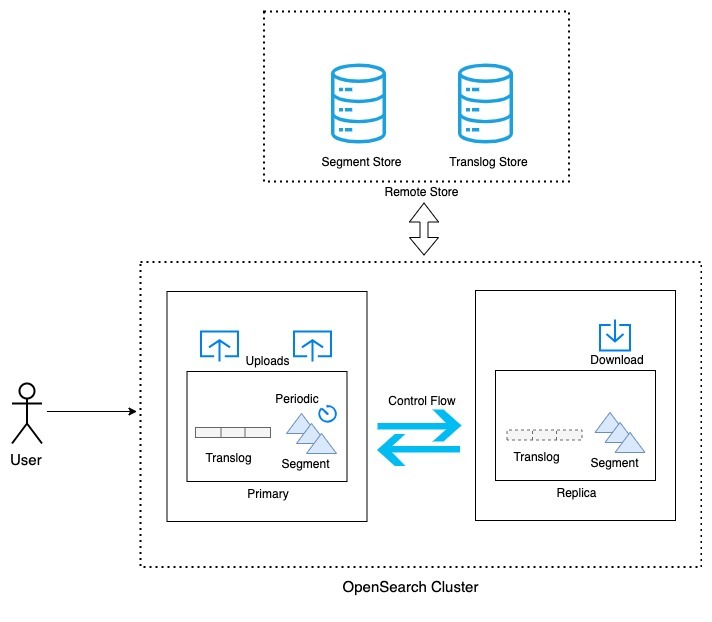
Design considerations
- Repository plugin: The existing repository interface is used to interact with the configured remote store. This enables you to use existing repository plugin implementations (Amazon S3, Azure Blob Storage, HDFS, Google Cloud Storage) out of the box.
- Segment replication: Remote-backed storage is only supported for the segment replication type. In document-based replication, the physical view of segments at primary and replica nodes can be different. This makes supporting remote store integration non-trivial whenever the primary changes because the remote store needs to be updated with the segments at the new primary node. This problem is solved with segment replication because primaries and replicas have the same set of physical segments.
Improved remote store integrations
- Enhanced replication and recovery: You can use the remote store in other OpenSearch flows that involve copying data from one node to another. For example, replicas download segments from the configured remote store during the replication and recovery flow. This helps to free up the primary node from data copying operations.
- Lightweight snapshots: To avoid data duplication in the remote store and snapshots, we added support for lightweight snapshots. Once enabled, a lightweight snapshot will create a checkpoint against the already uploaded data in the remote store. This significantly reduces resource consumption and the time required for the snapshot operation.
Things to consider
- Replication lag: As mentioned earlier, remote-backed storage is only supported for segment replication. Most trade-offs that come with using segment replication are resolved by integrating with remote storage. However, workloads that are sensitive to replication lag may need to be evaluated in the context of their use case before using remote storage.
- Choosing a remote store: The durability of the data depends on the durability properties of the configured remote store. In order to achieve higher durability, users should choose storage that offers higher durability compared to the data node.
What’s next
With all the indexed data and cluster state stored in the remote store, we can achieve more than just using it for backup purposes. Upcoming OpenSearch versions will add the following features:
- Searchable remote index: Searchable remote index will serve search queries from the data in the remote store without fully copying data to the local disk. For more information, see this RFC: https://github.com/opensearch-project/OpenSearch/issues/6528.
- Writable remote index: To make the remote index fully functional, supporting only search is not sufficient. The next step would be to support writing to the remote index. For more information, see this RFC: https://github.com/opensearch-project/OpenSearch/issues/7804.
- Point-in-time restore: Currently, the remote-backed storage feature supports restoring the latest state of the data. Point-in-time restore functionality depends on the snapshot interoperability feature. But given that snapshots are manual, the granularity of the restores will be the same as the period of the snapshots. We can provide deterministic and second/minute-level granularity by adding data checkpoints in the remote store.
References
- https://opensearch.org/docs/latest/tuning-your-cluster/availability-and-recovery/remote-store/index/
- https://opensearch.org/blog/segment-replication/





