
















Improving search efficiency and accuracy with the newest v2 neural sparse models
Neural sparse search is a novel and efficient method for semantic retrieval, introduced in OpenSearch 2.11. Sparse encoding models encode text into (token, weight) entries, allowing OpenSearch to build indexes and perform searches using Lucene’s inverted index. Neural sparse search is efficient and generalizes well in out-of-domain (OOD) scenarios. We are excited to announce the release of our v2 series neural sparse models:
- v2-distill model: This model reduces model parameters by 50%, resulting in lower memory requirements and costs. It increases ingestion throughput by 1.39 on GPU and 1.74x on CPU. The v2-distill architecture supports both the doc-only and bi-encoder modes.
- v2-mini model: This model reduces model parameters by 75%, also reducing memory requirements and costs. It increases ingestion throughput by 1.74x on GPUs and 4.18x on CPUs. The v2-mini architecture supports the doc-only mode.
Additionally, all v2 models achieve better search relevance. The following table compares search relevance between the v1 and v2 models. All v2 models are now available in both OpenSearch and Hugging Face.
| Model | Requires no inference for retrieval | Model parameters | AVG NDCG@10 |
|---|---|---|---|
| opensearch-neural-sparse-encoding-v1 | 133M | 0.524 | |
| opensearch-neural-sparse-encoding-v2-distill | 67M | 0.528 | |
| opensearch-neural-sparse-encoding-doc-v1 | ✔️ | 133M | 0.490 |
| opensearch-neural-sparse-encoding-doc-v2-distill | ✔️ | 67M | 0.504 |
| opensearch-neural-sparse-encoding-doc-v2-mini | ✔️ | 23M | 0.497 |
From v1 to v2 series models
The transition from v1 to v2 models in OpenSearch represents a significant advancement in neural sparse search capabilities.
Limitations of v1 models
For neural sparse search, the sparse encoding model is critical because it influences document scoring and ranking, directly impacting search relevance. The model’s inference speed also affects ingestion throughput and client-side search latency in bi-encoder mode. When we released neural sparse search in OpenSearch, we also launched two neural sparse models supporting doc-only and bi-encoder mode, respectively.
The primary challenge for v1 models is their large size. The v1 series models are based on the BERT base model, a 12-layer transformer with 133 million parameters. Compared to popular dense embedding models like tas-b and all-MiniLM-L6-v2, the inference cost of the v1 models is 2x to 4x higher. Therefore, reducing model parameters without compromising search accuracy became essential for the v2 series.
Knowledge distillation from an ensemble of heterogeneous teacher models
In neural models, performance is closely tied to the number of parameters. When using a smaller architecture, the training algorithm must be enhanced to offset any performance drop. For retrieval tasks, common techniques include pretraining and knowledge distillation:
- Pretraining: This involves training models on large datasets often constructed using specific rules. Examples of such dataset elements are
(title, body)pairs in news articles or(question, answer)pairs on Q&A websites. Pretraining enhances the model’s search relevance and ability to generalize. - Knowledge distillation: Some models are powerful but suffer from inefficiencies because of their large size or complex structure. An example of such a model is the cross-encoder reranker. Distillation transfers knowledge from these teacher models to smaller ones, preserving high performance while eliminating these drawbacks.
Dense retrievers are usually pretrained using Information Noise-Contrastive Estimation (InfoNCE) loss, which improves consistency and uniformity of dense representations. However, we found that InfoNCE loss does not enhance sparse embeddings in doc-only mode as it does for dense models. Instead, knowledge distillation loss is a more effective optimization technique for sparse encoding models. Finding a suitable teacher model for large-scale pretraining is challenging. Siamese encoders are generally not strong models, while cross-encoders struggle with handling large pretraining datasets. Inspired by the performance boost demonstrated by dense and lexical (sparse) hybrid search, we decided to combine a bi-encoder sparse retriever with Siamese dense models to create a strong teacher model. This model combines the strengths of heterogeneous retrievers and is efficient enough for pretraining. We plan to publish a paper detailing the training procedure.
Pretraining with knowledge distillation allows you to reduce the number of model parameters without compromising performance. Because we performed pretraining on a massive corpus1, the v2 series models achieved improved search relevance while significantly reducing the number of model parameters. We have released distill-BERT-based models for both the doc-only and bi-encoder modes (similar in size to tas-b) and a miniLM-based model for the doc-only mode (similar in size to all-MiniLM-L6-v2).
Accelerating model inference
The v2 models continue to use the transformer architecture, reducing the number of parameters by decreasing the number of layers and the hidden dimension size. As a result, the smaller v2 models offer higher ingestion throughput and lower search latency. We benchmarked the v2 models in ingestion and search scenarios using the MS MARCO passage retrieval dataset on an OpenSearch 2.16 cluster with three nodes running on r7a.8xlarge Amazon Elastic Compute Cloud (Amazon EC2) instances.
GPU deployment: We used an Amazon SageMaker GPU endpoint to host the neural sparse model, connecting to it using a remote connector. For the complete deployment code, see this example. The model was hosted on a g5.xlarge GPU instance.
CPU deployment: The model was deployed on all three nodes in the cluster.
In these experiments, we set the batch_size of the sparse_encoding ingestion processor to 2. We recorded the mean ingestion throughput and the p99 client-side latency for the Bulk API, using 20 clients for ingestion.
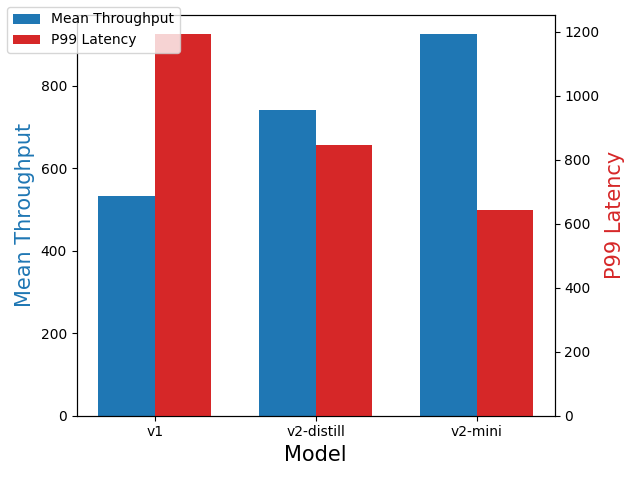
Remote deployment on a GPU
The bulk size was set to 24. The experiment results are presented in the following figure. Compared with the v1 model, the v2-distill model provided a 1.39x increase in mean throughput, and the v2-mini model provided a 1.74x increase in mean throughput.
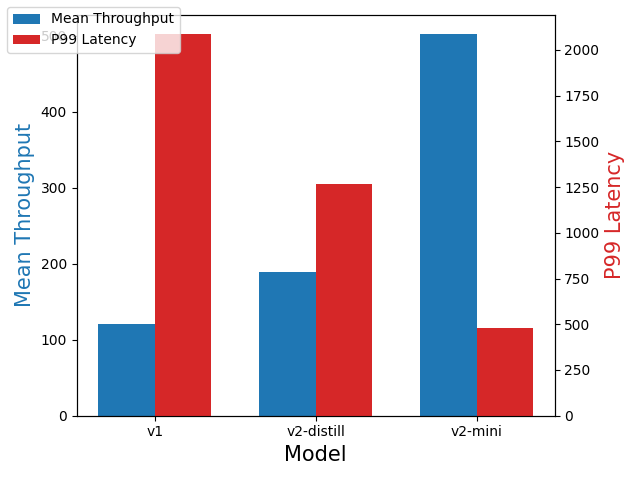
Local deployment on a CPU
The bulk size was set to 8. Compared with the v1 model, the v2-distill model provided a 1.58x increase in mean throughput, and the v2-mini model provided a 4.18x increase in mean throughput, as shown in the following figure.
Search
In these experiments, we ingested 1 million documents into an index and used 20 clients to perform concurrent searches. We recorded the p99 latency for both client-side search and model inference. We tested search performance for the bi-encoder mode.
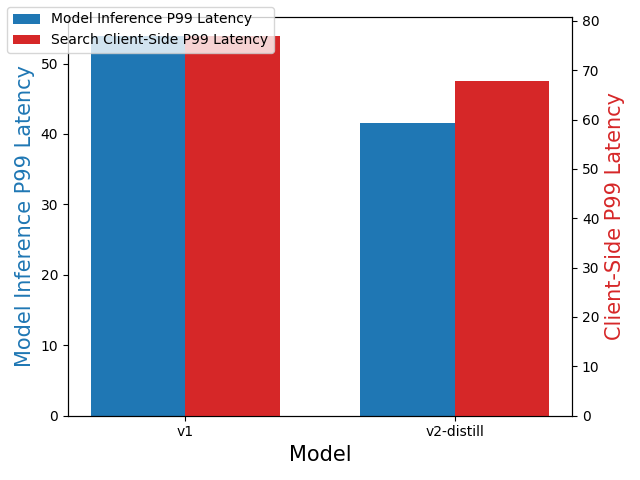
Remote deployment on a GPU
Compared with the v1 model, the v2-distill model decreased client-side search latency by 11.7% and model inference latency by 23%, as shown in the following figure.
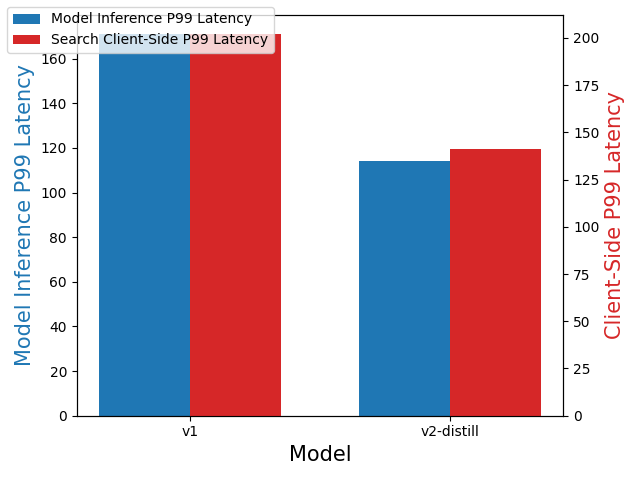
Local deployment on a CPU
Compared with the v1 model, the v2-distill model decreased client-side search latency by 30.2% and model inference latency by 33.3%, as shown in the following figure.
Search relevance benchmarks
Similarly to the tests described in our previous blog post, we evaluated model search relevance on a subset of the BEIR benchmark. The search relevance results are provided in the following table. All v2-series models outperform the v1 models with the same architecture, indicating that distillation from a heterogeneous teacher model is a more effective method than pretraining using InfoNCE loss.
| Model | Average | Trec-Covid | NFCorpus | NQ | HotpotQA | FiQA | ArguAna | Touche | DBPedia | SciDocs | FEVER | Climate FEVER | SciFact | Quora |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| opensearch-neural-sparse-encoding-v1 | 0.524 | 0.771 | 0.360 | 0.553 | 0.697 | 0.376 | 0.508 | 0.278 | 0.447 | 0.164 | 0.821 | 0.263 | 0.723 | 0.856 |
| opensearch-neural-sparse-encoding-v2-distill | 0.528 | 0.775 | 0.347 | 0.561 | 0.685 | 0.374 | 0.551 | 0.278 | 0.435 | 0.173 | 0.849 | 0.249 | 0.722 | 0.863 |
| opensearch-neural-sparse-encoding-doc-v1 | 0.490 | 0.707 | 0.352 | 0.521 | 0.677 | 0.344 | 0.461 | 0.294 | 0.412 | 0.154 | 0.743 | 0.202 | 0.716 | 0.788 |
| opensearch-neural-sparse-encoding-doc-v2-distill | 0.504 | 0.690 | 0.343 | 0.528 | 0.675 | 0.357 | 0.496 | 0.287 | 0.418 | 0.166 | 0.818 | 0.224 | 0.715 | 0.841 |
| opensearch-neural-sparse-encoding-doc-v2-mini | 0.497 | 0.709 | 0.336 | 0.510 | 0.666 | 0.338 | 0.480 | 0.285 | 0.407 | 0.164 | 0.812 | 0.216 | 0.699 | 0.837 |
Registering and deploying v2 models
OpenSearch now provides pretrained v2 sparse encoding models. Depending on the search mode, you need to register different models:
- In doc-only mode, you need to register a sparse encoding model for ingestion and a tokenizer for search.
- In bi-encoder mode, you need to register a sparse encoding model that will be used for ingestion and search.
For detailed setup instructions and tutorials, see Neural sparse search.
Registering and deploying models in doc-only mode
To register and deploy models in doc-only mode, use the following steps.
-
Register and deploy a sparse encoding model for ingestion:
POST /_plugins/_ml/models/_register?deploy=true { "name": "amazon/neural-sparse/opensearch-neural-sparse-encoding-doc-v2-distill", "version": "1.0.0", "model_format": "TORCH_SCRIPT" } -
Register and deploy a tokenizer for search:
POST /_plugins/_ml/models/_register?deploy=true { "name": "amazon/neural-sparse/opensearch-neural-sparse-tokenizer-v1", "version": "1.0.1", "model_format": "TORCH_SCRIPT" } -
Get model IDs for the model and tokenizer by calling the Tasks API:
GET /_plugins/_ml/tasks/{task_id}
Registering and deploying models in bi-encoder mode
To register and deploy models in bi-encoder mode, use the following steps.
-
Register and deploy a sparse encoding model for ingestion and search:
POST /_plugins/_ml/models/_register?deploy=true { "name": "amazon/neural-sparse/opensearch-neural-sparse-encoding-v2-distill", "version": "1.0.0", "model_format": "TORCH_SCRIPT" } -
Get the model ID for the sparse encoding model by calling the Tasks API:
GET /_plugins/_ml/tasks/{task_id}
Further reading
For more information about neural sparse search, see these previous blog posts:
- Improving document retrieval with sparse semantic encoders
- A deep dive into faster semantic sparse retrieval in OpenSearch 2.12
- Introducing the neural sparse two-phase algorithm
- Neural Sparse is now available in Hugging Face Sentence Transformers
-
For pretraining, we selected a portion of the sentence transformer training data. We removed any data that also appeared in BEIR in order to maintain a zero-shot evaluation environment. ↩




