
















Improve search relevance with hybrid search, generally available in OpenSearch 2.10
In an earlier blog post, a group of Amazon scientists and engineers described methods of combining keyword-based search with dense vector search in order to improve search relevance. With OpenSearch 2.10, you can tune search relevance by using hybrid search, which combines and normalizes query relevance scores. In this post, we’ll describe what hybrid search is and how to use it. Further, we’ll provide benchmarking test results that demonstrate how hybrid search improves search relevance.
Combining lexical and semantic search
The OpenSearch search engine supports both lexical and semantic search. Each of these techniques has its advantages and disadvantages, so it is natural to try to combine them so that they complement each other.
The naive approach to combination—an arithmetic combination of the scores returned by each system—doesn’t work:
- Different query types provide scores on different scales. For instance, a full-text
matchquery score can be any positive number, while aknnorneural-searchquery score is typically between 0.0 and 1.0. - OpenSearch normally calculates scores at the shard level. However, there still needs to be a global normalization of scores coming from all shards.
The naive approach
Before OpenSearch 2.10, you could attempt to combine text search and neural search results by using one of the compound query types. However, this approach does not work well.
To demonstrate why that is, consider searching a database of images for the Washington/Wells station, a train station in the Chicago “L” system. You might start by searching for the text “Washington Wells station” and combining neural and match queries as Boolean query clauses:
"query": {
"bool": {
"should": [
{
"match": {
"text": {
"query": "Washington Wells station"
}
}
},
{
"neural": {
"passage_embedding": {
"query_text": "Washington Wells station",
"model_id": "3JjYbIoBkdmQ3A_J4qB6",
"k": 100
}
}
}
]
}
}
In this example, the match query scores are in the [8.002, 11.999] range and the neural query scores are in the [0.014, 0.016] range, so the match query scores dominate the neural query scores. As a result, the neural query has little to no effect on the final scores, which are in the [8.019, 11.999] range. In the following image, note that the Boolean query results (right) are the same as the BM25 match query results (center) and do not include any matches from the neural query (left).
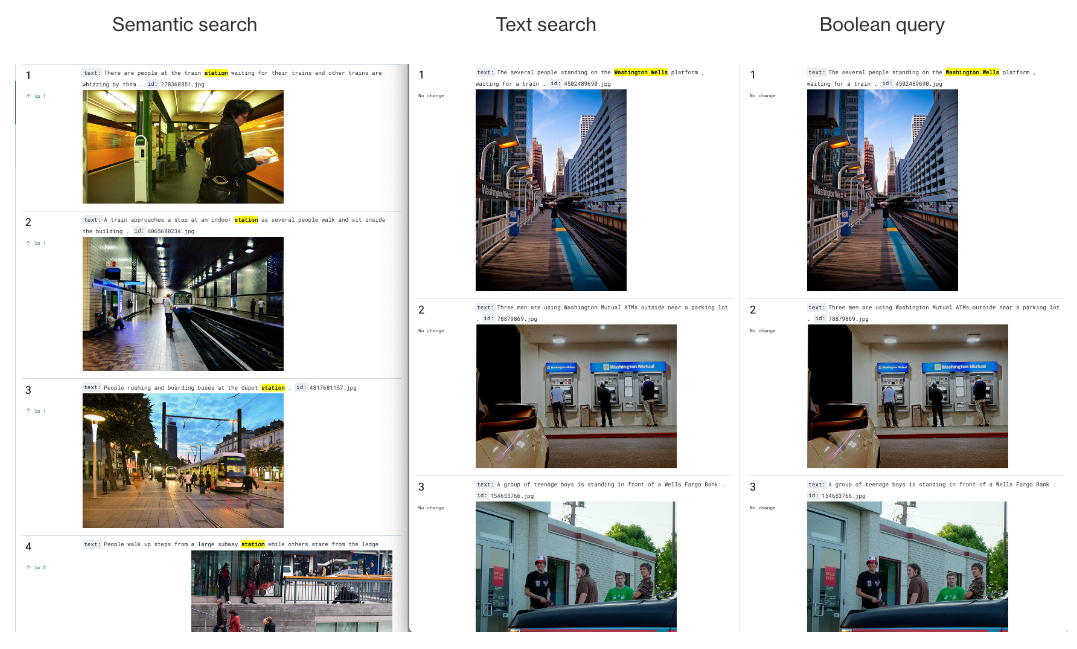
Combining a neural query with a compound query presents the same problem because of the difference in the scales.
Ideally, search results would prioritize the first match from the BM25 query (the Washington/Wells station) followed by other train stations.
Combining query clauses with hybrid search
Let’s recall the problems presented by the naive approach: scores being on different scales and a shard being unaware of another shard’s results. The first problem can be solved by normalizing scores and the second by combining scores from all shards. We need a query type that will execute queries (in our example, the text search and neural query) separately and collect shard-level query results. Query results from all shards should be collected in one place, normalized for each query separately, and then combined into a final list. This is exactly what we proposed in the hybrid query search RFC.
At a high level, hybrid search consists of two main elements:
- The hybrid query provides a way to define multiple individual queries, execute those queries, and collect results from each shard.
- The normalization processor, which is part of a search pipeline, collects the results from all shards at the coordinator node level, normalizes scores for each of the queries, and combines scores into the final result.
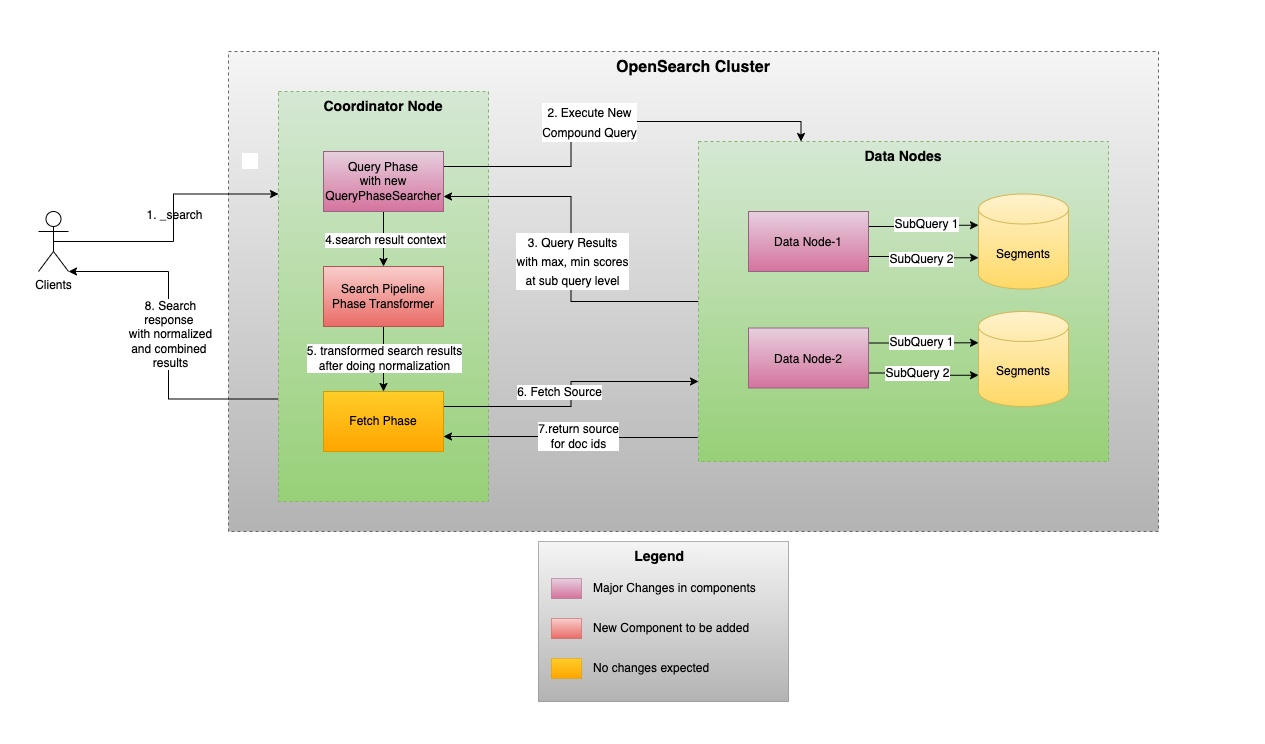
The following diagram shows how hybrid search works at a high level. During the query phase, the coordinator node sends queries to multiple data nodes, where the results are collected. When the query phase finishes, the normalization processor normalizes and combines the results from all queries and all nodes. The overall results are sent to a fetch phase, which retrieves the document content.
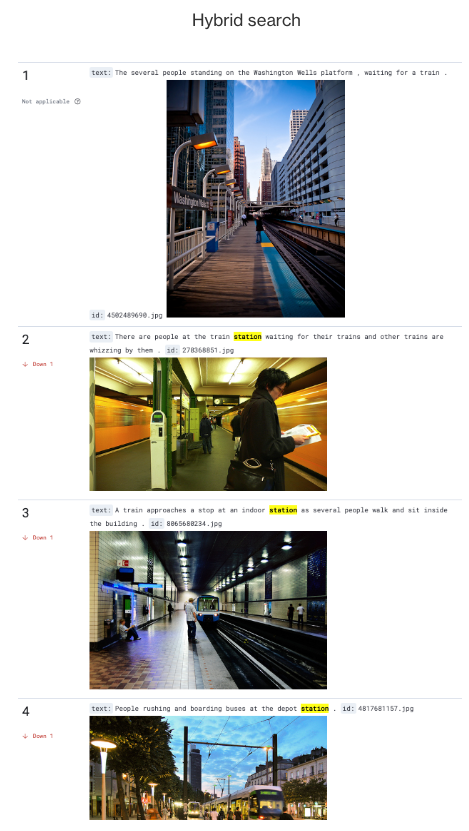
You can observe hybrid search in action by using it to search for images of the Washington/Wells station:
"query": {
"hybrid": {
"queries": [
{
"match": {
"text": {
"query": "Washington Wells station"
}
}
},
{
"neural": {
"passage_embedding": {
"query_text": "Washington Wells station",
"model_id": "3JjYbIoBkdmQ3A_J4qB6",
"k": 5
}
}
}
]
}
}
The following image shows the results generated by the hybrid query, which combine the most relevant matches from both the BM25 query (featuring an image of the Washington/Wells station) and the neural query (showcasing other train stations).
How to use hybrid query
Hybrid search is generally available in OpenSearch 2.10; no additional settings are required.
Before you can use hybrid search, you need to create a search pipeline with the normalization processor:
PUT /_search/pipeline/norm-pipeline
{
"description": "Post-processor for hybrid search",
"phase_results_processors": [
{
"normalization-processor": {
"normalization": {
"technique": "l2"
},
"combination": {
"technique": "arithmetic_mean"
}
}
}
]
}
The normalization processor supports the followings techniques:
min-maxandl2for score normalizationarithmetic mean,geometric mean, andharmonic meanfor score combination
You can set additional parameters for score combination to define weights for each query clause. Additionally, you can create multiple search pipelines, each featuring distinct normalization processor configurations, as dictated by your specific needs. For more details on supported techniques and their definitions, see Normalization processor.
To run a hybrid query, use the following syntax:
POST my_index/_search?search_pipeline=<search_pipeline>
{
"query": {
"hybrid": [
{}, // First Query
{}, // Second Query
... // Other Queries
]
}
}
For example, the following hybrid query combines a match query with a neural query to search for the same text:
POST my_index/_search?search_pipeline=norm-pipeline
{
"_source": {
"exclude": [
"passage_embedding"
]
},
"query": {
"hybrid": {
"queries": [
{
"match": {
"title_key": {
"query": "Do Cholesterol Statin Drugs Cause Breast Cancer"
}
}
},
{
"neural": {
"passage_embedding": {
"query_text": "Do Cholesterol Statin Drugs Cause Breast Cancer",
"model_id": "1234567890",
"k": 100
}
}
}
]
}
},
"size": 10
}
For more information and examples of hybrid search, see Hybrid query.
Benchmarking score accuracy and performance
To benchmark the score accuracy and performance of hybrid search, we chose seven datasets that cover different domains and vary in the main dataset parameters, such as query number and document length. Running benchmarks on the same datasets as in our earlier blog post allowed us to use the previous data as a baseline.
We built the hybrid query as a combination of two queries: a neural search query and a text search match query.
For the neural query, we generated text embeddings using neural search data ingestion. We used pretrained and fine-tuned transformers to generate embeddings and run search queries. For the HNSW algorithm in k-NN search, we used k = 100.
For text search, we used a text field with one analyzer (english).
The cluster configuration consisted of 3 r5.8xlarge data nodes and 1 c4.2xlarge leader node.
You can find all scripts that we used for benchmarks in this repository.
Score accuracy results
To benchmark score accuracy, we chose the nDCG@10 metric because it’s widely used to measure search relevance. The following table displays the benchmarking results.
| BM25 | TAS-B | Theoretical baseline | Hybrid query | Fine-tuned transformer | Theoretical baseline, fine-tuned | Hybrid query, fine-tuned | |
|---|---|---|---|---|---|---|---|
| NFCorpus | 0.3208 | 0.3155 | 0.357 | 0.3293 | 0.301 | 0.37 | 0.3433 |
| Trec-Covid | 0.6789 | 0.4986 | 0.731 | 0.7376 | 0.577 | 0.79 | 0.765 |
| Scidocs | 0.165 | 0.149 | 0.17 | 0.173 | 0.154 | 0.184 | 0.1808 |
| Quora | 0.789 | 0.835 | 0.847 | 0.8649 | 0.855 | 0.874 | 0.8742 |
| Amazon ESCI | 0.081 | 0.071 | 0.088 | 0.088 | 0.074 | 0.091 | 0.0913 |
| DBPedia | 0.313 | 0.384 | 0.395 | 0.391 | 0.342 | 0.392 | 0.3742 |
| FiQA | 0.254 | 0.3 | 0.289 | 0.3054 | 0.314 | 0.364 | 0.3383 |
| average % change vs. BM25 | -6.97% | 7.85% | 8.12% | -2.34% | 14.77% | 12.08% |
Score performance results
For performance benchmarks, we measured the time taken to process a query on the server, in milliseconds. The following table displays the benchmarking results.
| p50 | p90 | p99 | |||||||
| Boolean query (baseline) | Hybrid query | Difference, ms | Boolean query (baseline) | Hybrid query | Difference, ms | Boolean query (baseline) | Hybrid query | Difference, ms | |
| NFCorpus | 35.1 | 37 | 1.9 | 53 | 54 | 1 | 60.8 | 62.3 | 1.5 |
| Trec-Covid | 58.1 | 61.6 | 3.5 | 66.4 | 70 | 3.6 | 70.5 | 74.6 | 4.1 |
| Scidocs | 54.9 | 57 | 2.1 | 66.4 | 68.6 | 2.2 | 81.3 | 83.2 | 1.9 |
| Quora | 61 | 69 | 8 | 69 | 78 | 9 | 73.4 | 84 | 10.6 |
| Amazon ESCI | 49 | 50 | 1 | 58 | 59.4 | 1.4 | 67 | 70 | 3 |
| DBPedia | 100.8 | 107.7 | 6.9 | 117 | 130.9 | 13.9 | 129.8 | 150.2 | 20.4 |
| FiQA | 53.9 | 56.9 | 3 | 61.9 | 65 | 3.1 | 64 | 67.7 | 3.7 |
| % change vs. Boolean query | 6.40% | 6.96% | 8.27% | ||||||
As shown in the preceding table, hybrid search improves the result quality by 8–12% compared to keyword search and by 15% compared to natural language search. Simultaneously, a hybrid query exhibits a 6–8% increase in latency compared to a Boolean query when executing the same inner queries.
Our experimental findings indicate that the extent of improvement in score relevance is contingent upon the size of the sampled data. For instance, the most favorable results are observed when size is in the [100 .. 200] range, whereas larger values of size do not enhance relevance but adversely affect latency.
Conclusions
In this blog post, we have presented a series of experiments that show that hybrid search produces results that are very close to theoretical expectations and in most cases are better than the results of individual queries alone. Hybrid search produces a certain increase in latency, which will be addressed in future versions (you can track the progress of this enhancement in this GitHub issue).
It’s important to remember that datasets have different parameters and that hybrid search may not consistently improve results for some datasets. Conversely, experimenting with different parameters—for instance, selecting higher values of k or a different space_type for neural search—may lead to better results.
We’ve seen that the following conclusions may be applied to most datasets:
- For semantic search, a hybrid query with normalization produces better results compared to neural search or text search alone.
- The combination of
min-maxscore normalization andarithmetic_meanscore combination achieves the best results, compared to other techniques. - In most cases, increasing the value of
kin the k-NN data type leads to better results up to a certain point, but after that, there is no increase in relevance. At the same time, high values ofkincrease search latency, so from our observations, it’s better to choose a value ofkbetween 100 and 200. - The best results are produced when
innerproductis specified as a space type for k-NN vector fields. This may be because our models were trained using the inner product similarity function. - An increase in search relevance leads to a 6–8% increase in latency, which should be acceptable in most cases.
In general, as our experiments demonstrated, hybrid search produces results that are very close to the ones described by the science team in our earlier blog post, so all of their conclusions are applicable to hybrid search.
Next steps
We have identified several areas of improvement for hybrid search, and we’re planning to address them in future OpenSearch versions. In the short term, a good starting point is to improve performance by running individual queries of the main hybrid query in parallel instead of sequentially. This should significantly improve latency, especially when all inner queries have similar running times.
We are considering including the following improvements in future versions:
- Executing individual queries in parallel (see issue #279 and issue #281).
- Adding more configuration options and parameters to the normalization processor to allow more control over combined results. For instance, we could add the ability to specify a minimum score required in order for documents to be returned in the results, which will avoid returning non-competitive hits (see issue #299).
- Supporting results pagination (see issue #280).
- Supporting filters in the hybrid query clause (see issue #282). It’s possible to define a filter for each inner query individually, but it’s not optimal for a filter condition to be the same for all inner queries.
- Adding more benchmark results for larger datasets so we can provide recommendations on using hybrid search in various configurations.
Dataset statistics
The following table provides further details of the test datasets used for benchmarking.
| Dataset | Average query length | Median query Length | Average passage length | Median passage Length | Number of passages | Number of test queries |
|---|---|---|---|---|---|---|
| NFCorpus | 3.29 | 2 | 22.098 | 224 | 3633 | 323 |
| Trec-Covid | 10.6 | 10 | 148.64 | 155 | 171332 | 50 |
| Scidocs | 9.44 | 9 | 167.24 | 151 | 25657 | 1000 |
| Quora | 9.531 | 9 | 11.46 | 10 | 522931 | 10000 |
| Amazon ESCI | 3.89 | 4 | 179.87 | 137 | 482105 | 8956 |
| DBPedia | 5.54 | 5 | 46.89 | 47 | 4635922 | 400 |
| FiQA | 10.94 | 10 | 132.9 | 90 | 57638 | 648 |
References
- The ABCs of semantic search in OpenSearch: Architectures, benchmarks, and combination strategies. https://opensearch.org/blog/semantic-science-benchmarks.
- [RFC] High Level Approach and Design For Normalization and Score Combination. https://github.com/opensearch-project/neural-search/issues/126.
- Building a semantic search engine in OpenSearch. https://opensearch.org/blog/semantic-search-solutions/.
- An Analysis of Fusion Functions for Hybrid Retrieval. https://arxiv.org/abs/2210.11934.
- Beir benchmarking for Information Retrieval. https://github.com/beir-cellar/beir.



