
















Get started with OpenSearch 2.11
OpenSearch 2.11 is now available, with exciting new capabilities for observability applications, an expanded selection of search tools, enhancements to data durability, and more, along with new experimental functionality to explore. For a complete view of what’s new in this release, see the release notes, and you can give OpenSearch Dashboards a try on OpenSearch Playground.
An easier way to infuse multimodal search into your applications
This release introduces text and image multimodal search using neural search. This functionality allows users to search image and text pairs, like product catalog items (product image and description), based on visual and semantic similarity. This enables new search experiences that can deliver more relevant results. For instance, users can search for “white blouse” to retrieve product images—the machine learning (ML) model that powers this experience is able to associate semantics and visual characteristics. Users can also search by image to retrieve visually similar products or search by both text and image to find the products most similar to a particular product catalog item. You can now build these capabilities into your application to connect directly to multimodal models and run multimodal search queries without having to build custom middleware. See the multimodal search documentation for guidance on how to get started with multimodal semantic search, and look out for more input types to be added to this functionality in future releases.
Choose the best retrieval method for semantic search applications
Previously, OpenSearch offered only a dense retrieval approach for text-based vector search. With this release, search practitioners can now choose between sparse retrieval or dense retrieval methods for semantic search applications.
Each method presents tradeoffs for users, depending on their application; for example, dense retrieval typically delivers high search relevance while consuming more memory and compute resources and has higher latencies. In comparison, the new sparse retrieval functionality offers two modes with different advantages: a document-only mode can deliver low-latency performance more comparable to BM25 search, with limitations for advanced syntax as compared to dense methods, and a bi-encoder mode can maximize search relevance while performing at higher latencies. With this update, users can now choose the method that works best for their performance, accuracy, and cost requirements. For an in-depth exploration of each method and their advantages for different workloads, stay tuned for an upcoming blog post.
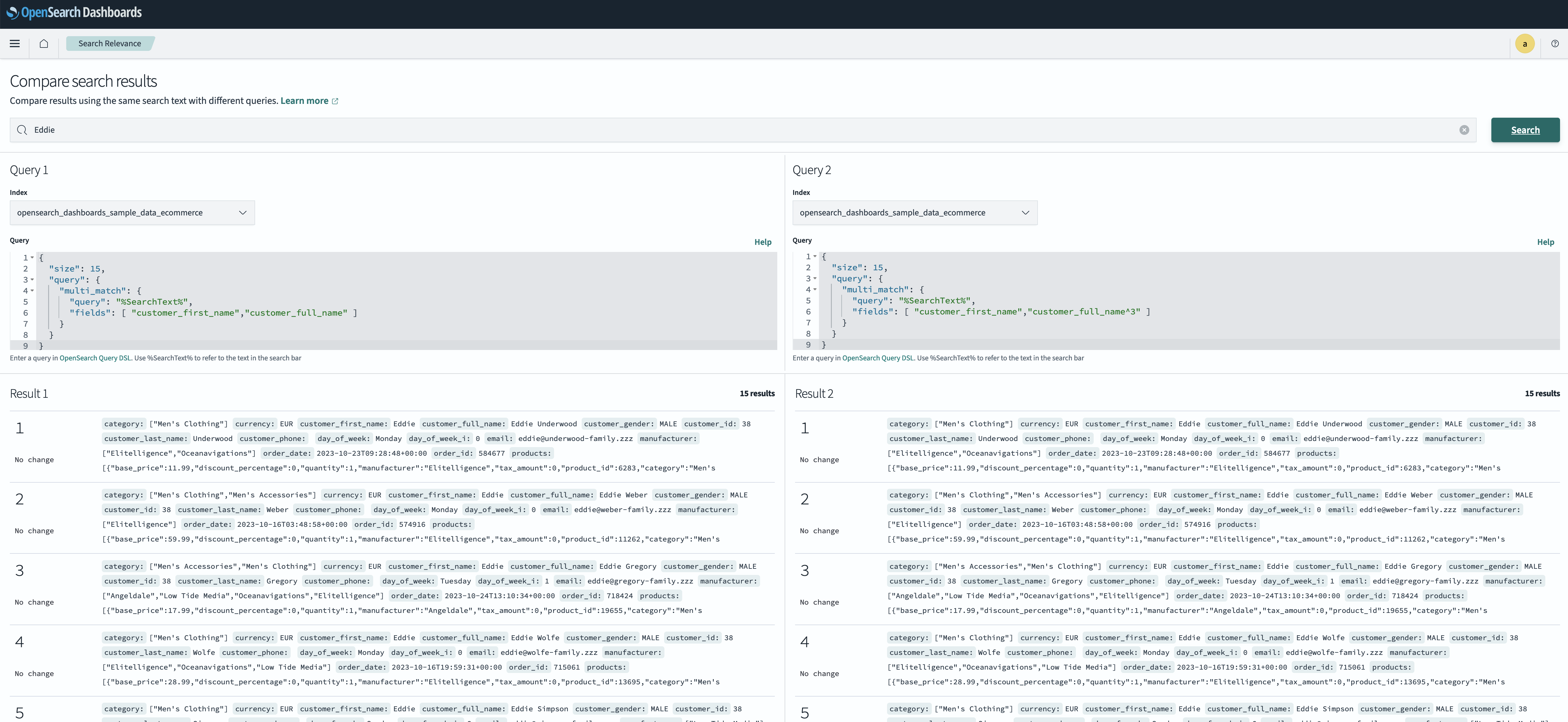
Compare and tune your search results
Introduced in OpenSearch 2.4 as experimental functionality, this release makes the search comparison tool generally available for production workloads. This tool lets you compare the results of two different search queries side by side in OpenSearch Dashboards, as shown in the following example UI. As an example, you can compare the results of a lexical search against the results from a semantic search query so that you can view both rankings and tune your results accordingly.
Protect data efficiently with interoperability between snapshots and remote-backed storage
Today, OpenSearch offers two built-in ways to enhance data durability: remote-backed storage, which gives you the option to automatically store all transactions on a per-index basis using your choice of cloud storage services, and snapshots, which let you create an on-demand snapshot of a cluster’s indexes and metadata in a configured repository. With this feature, you have the option to use snapshots more efficiently, with less demand on compute resources, by taking snapshots that refer to data in your remote-backed repository rather than duplicating the data in full.
Usability improvements for Security Analytics
Following from the results of a recent usability study, this release brings updates to the user experience designed to make it easier to get started with Security Analytics. A new workflow simplifies the process of creating threat detectors and setting up alerts within OpenSearch Dashboards, reducing the number of steps and clarifying certain form fields. Another change adds categories to log types, organizing prepackaged and custom logs into predefined categories for easier filtering and sorting.
Improving the security posture of OpenSearch Dashboards
OpenSearch 2.11 marks the culmination of a long-term project with the goal of removing dependencies on AngularJS from OpenSearch Dashboards. With AngularJS having reached end-of-life, this step will help to modernize and improve the security posture of OpenSearch Dashboards. For a detailed view of what has changed and how it may affect users, please review this recently published notice in GitHub.
Bringing authorization to the REST layer for plugin development
REST layer authorization empowers plugin developers to establish secure access controls for REST endpoints in addition to transport layer authorization. Previously, OpenSearch exclusively enforced authorization checks at the transport layer. Given that extensions solely interact with the OpenSearch cluster through the REST layer, the introduction of extensions necessitated the implementation of authorization checks at that layer. Now offered as an independent feature, this enables plugin developers to incorporate routes with an additional layer of security. Integration of this functionality with the extension framework is currently under development.
Experimental features
OpenSearch 2.11 includes experimental features designed to allow users to preview new tools before they are generally available. Experimental features should not be used in a production environment.
Track OpenSearch requests with traces
OpenSearch 2.11 introduces the ability to trace OpenSearch requests and tasks as an experimental functionality. With this release, OpenSearch introduces a new framework that allows developers to follow OpenSearch requests and tasks as they traverse components and services across the distributed architecture. Users can also enable this functionality in order to trace their requests and monitor their paths through the system, measure request latencies, and more. This release enables this functionality at the network layer, REST layer, and transport layer. As development of the feature continues, additional capabilities will address collecting trace and span data at different levels of granularity and with different code paths. Refer to the documentation to learn more and see how you can explore these capabilities. To share feedback, please see our request for comments.
Customize pipelines for retrieval augmented generation
Enhancing the conversational search functionality introduced in OpenSearch 2.10 as an experimental toolkit, this release introduces several new parameters that can be used to customize retrieval augmented generation (RAG) pipelines. These optional parameters provide core logic that allows you to adapt the way OpenSearch interacts with large language models (LLMs) as part of generative artificial intelligence (GenAI) applications. See the documentation for this feature to explore the available parameters.
The latest version of OpenSearch is ready for download! You can find out more about these features and many others in the release notes and the documentation release notes as well as the documentation. OpenSearch Playground offers a turnkey option for exploring the visualization toolkit before downloading it. Look for upcoming blog posts that dive deeper into the new functionality delivered in OpenSearch 2.11.
