
















Exploring OpenSearch 2.10
OpenSearch 2.10 is ready to download, with new tools for search, security, and machine learning applications, improved storage durability options, a better way to analyze and visualize your data in OpenSearch Dashboards, and more. This release also brings exciting new experimental functionality, including built-in support for conversational search applications. For a comprehensive look at everything that’s new, check out the release notes. And as always, you can try out OpenSearch’s visualization tools on OpenSearch Playground.
Improve durability with remote-backed storage
With OpenSearch 2.10, remote-backed storage is generally available, offering a production-ready alternative to snapshots or replica copies for durable data backup. Remote-backed storage gives you the option to automatically back up all transactions on a per-index basis to durable remote storage using your choice of cloud storage services. Now you can deploy remote-backed storage for your OpenSearch clusters using Amazon Simple Storage Service (Amazon S3), Azure Blob Storage, Google Cloud Storage, or Oracle Cloud Infrastructure (OCI) Object Storage.
Remote-backed storage comes fully integrated with OpenSearch segment replication, offering improved performance and durability while reducing demand for storage and compute resources. This enables the option to select remote-backed storage as the source for replication, further reducing compute resources on ingest. Also with the release, segment replication and remote-backed storage indexes can support heterogeneous Lucene versions, which is required for rolling version upgrades.
Improve search relevance
OpenSearch 2.9 made neural search and search pipelines generally available. This release builds on those tools with the addition of a normalization processor and hybrid query functionality. Now you can improve search relevance by combining the relevance scores of lexical queries with natural language-based k-NN vector search queries. As lexical and semantic queries return relevance scores on different scales, this release offers the ability to normalize relevance scores, making it easier than ever to build hybrid search applications on OpenSearch. By affording control over how relevance scores are normalized and combined, OpenSearch 2.10 offers search practitioners greater ability to tune their hybrid search results for maximum relevance. For a deeper look at combination and normalization and its benefits for semantic search, please see the blog post The ABCs of semantic search in OpenSearch. For a tutorial on implementing semantic search in OpenSearch, see this recent update to our documentation.
Access and analyze more log data in Security Analytics with custom log types
Since the release of OpenSearch Security Analytics, the toolkit has added support for a number of popular security log sources. With this release, OpenSearch addresses community feedback with the addition of custom log types. A new CRUD API lets you define your own custom log types and use them as you would other logs—to build detectors, create custom rules, provide additional mappings, and more.
Experience an updated OpenSearch Dashboards UI
As part of our efforts to modernize the visualization and dashboarding experience, we are releasing a new visual theme with version 2.10. The theme updates typography, colors, and actions, creating a more user-friendly Dashboards environment and reducing the cognitive load for the user. These updates apply to the new “Next (preview)” theme, including light and dark mode designs. You can control these appearance settings in the Advanced settings. We welcome your feedback on the forums, especially in advance of making the dark mode the default mode, starting with version 2.11. Try out the new experience today on OpenSearch Playground.
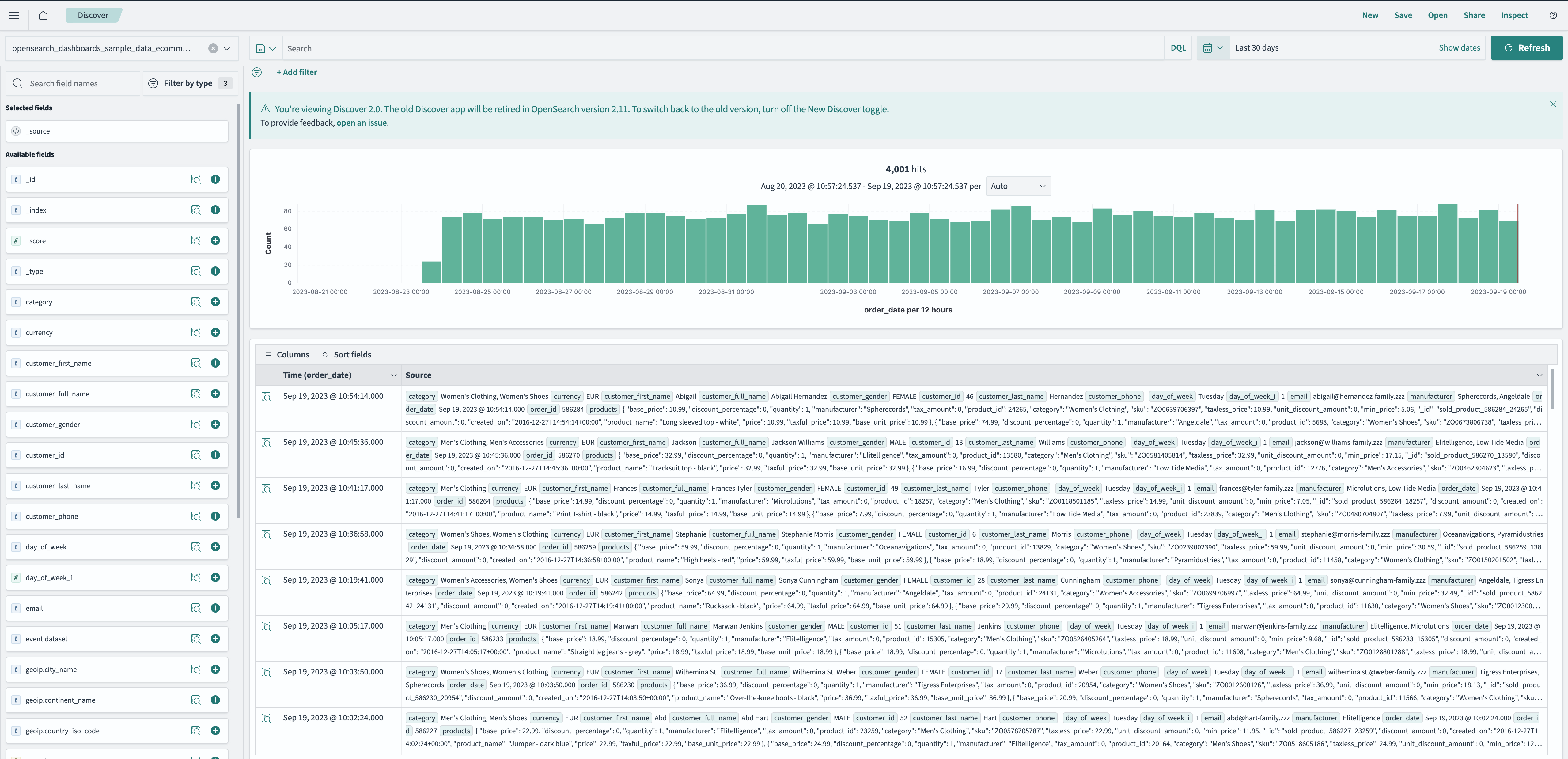
Turn data into insights with the new Discover
This release brings more usability improvements and significant backend updates to the Discover tool in Dashboards. These improvements build on our efforts to design a more intuitive and cohesive tool. You now have the option to use this new version of the Discover tool or the previous version. This new experience is anticipated to be the default starting with OpenSearch 2.11, so please leave your feedback by selecting the feedback link directly within the the tool. Try out the new experience today on OpenSearch Playground.
Keep up to date with GeoIP data
Also included in this release is a new way to enrich your data with geographical information. With the new IP2Geo processor, OpenSearch can retrieve information about the geographical location of an IPv4 or IPv6 address and add that information to incoming data during ingest or enrich the data at a later time, if needed. OpenSearch previously pulled geographic IP data from a static database, which could become out of date. With this processor, up-to-date geographic IP data is accessed from external databases made available by MaxMind.
New experimental features
OpenSearch 2.10 includes new experimental features designed to allow users to preview new tools before they are generally available. Experimental features should not be used in a production environment.
Build conversational search applications with a built-in toolkit
OpenSearch 2.10 brings support for conversational search applications as an experimental toolkit included with the ML Commons plugin. Building on top of the vector database functionality inherent in OpenSearch and the search pipelines functionality delivered in 2.9, these tools include new APIs that enable conversational search and conversational memory as well as integrations with search pipelines that allow the use of conversational memory and large language models (LLMs) to answer questions. With these new APIs, developers will be able to build conversational search applications, such as knowledge-based search, informational chatbots, or other generative AI applications powered by retrieval augmented generation (RAG) workflows. To learn more or share feedback, see the GitHub issue. A special thank you to Austin Lee, Henry Lindeman, and the Aryn.ai team for this contribution!
Improve search performance with concurrent segment search
With the default approach, OpenSearch executes search requests sequentially across all segments on each shard. With the experimental concurrent segment search functionality, you’ll have the option to query index segments in parallel at the shard level. This can offer improved latency for many types of search queries, such as long-running requests that contain aggregations or large ranges. There are several ways to enable concurrent segment search, depending on installation type; for more information, please refer to the documentation. To share feedback on this feature, see the associated GitHub issue.
Getting started with OpenSearch 2.10
You can find the latest version of OpenSearch here. There’s more to learn about these capabilities and many other new features in the release notes, documentation release notes, and documentation, and you can use the latest OpenSearch Dashboards views on OpenSearch Playground. We invite your feedback on this release on the community forum!
