
















Explore OpenSearch 2.14
OpenSearch 2.14 is live and ready for download! The latest version of OpenSearch is filled with updates that increase performance, improve usability, expand access to data sources, and help users build better search and machine learning (ML) applications. Read on for an overview of some of OpenSearch’s exciting new capabilities, and check out the release notes and our updated documentation for a deeper dive. As always, the latest version of OpenSearch Dashboards is ready for you to start exploring on OpenSearch Playground.
This release announcement is organized a little differently than previous ones. A recent request for comments explores different ways to organize our public roadmap, with the goals of streamlining the process of OpenSearch contributions, affording better visibility into the direction of the project, and further aligning contributions to the priorities of the OpenSearch community. The proposal categorizes contributions across several proposed themes.
The roadmap will begin to align with these themes as contributions are tagged and labeled with the updated categories. If you have feedback or suggestions, please share your thoughts in the RFC. We hope the updated roadmap will help community members and those looking to learn more about OpenSearch gain a clear understanding of the scope of planned features and how they support the project’s direction. With that in mind, this announcement organizes the feature updates for 2.14 in accordance with these themes.
Cost, performance, scale
The following features reflect the project’s priorities for helping users improve cost, performance, and scale for their OpenSearch deployments.
Boost performance for hybrid search use cases
Hybrid search, introduced in OpenSearch 2.10, brings together neural search using vector similarity (k-NN) with the advantages of lexical search to provide higher-quality results than when using either technique alone. As users increasingly take advantage of this functionality, we continue to work on optimizing its performance. In OpenSearch 2.14, we are releasing improvements to hybrid search that in some cases may increase performance by as much as 4x.
Accelerate date histogram queries with multi-range traversal
OpenSearch 2.14 adds to the significant increases in date histogram query performance that came with OpenSearch 2.12. That release brought 10x to 50x speed increases on the nyc_taxis benchmark workload for queries without sub-aggregations; this release adds multi-range traversal, a performance optimization that has demonstrated gains in date histogram query performance of up to 70% on the http_logs workload and 20–40% improvements on nyc_taxis, as shown in the benchmark results below. This optimization also addresses a performance regression noted in the PubMed Central (PMC) benchmark for these queries.
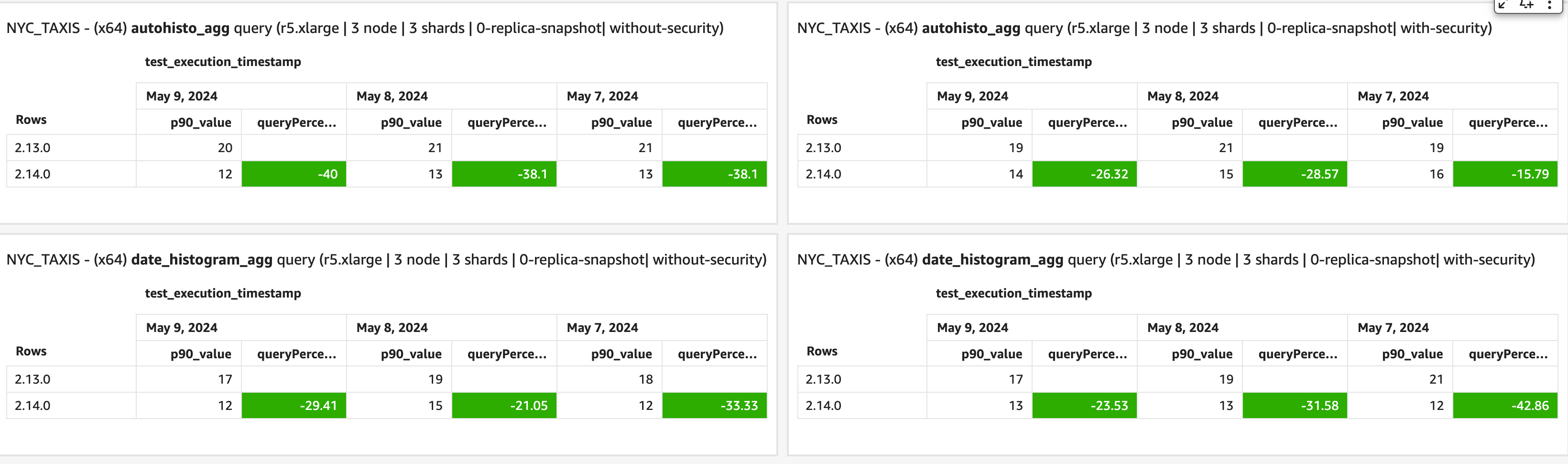 Performance increases for aggregation queries from 2.13 release to 2.14 release
Performance increases for aggregation queries from 2.13 release to 2.14 release
Improve search efficiency with tiered caching within the request cache (Experimental)
OpenSearch 2.14 introduces experimental support for tiered caching within the request cache. OpenSearch uses on-heap caches like the RequestCache to speed up data retrieval, significantly enhancing search latencies. However, the size of an on-heap cache is restricted by the available memory on a node. This limitation can become apparent with larger datasets, leading to cache evictions and misses. To mitigate this, this release introduces a tiered cache system for the IndicesRequestCache, enabling caching of much larger datasets. The tiered cache framework consists of multiple levels, each with its own size and performance characteristics. Evicted items from the upper, faster tiers, such as the on-heap cache, are moved to the lower, slower tiers, like the disk cache. Although the lower tier offers more storage capacity, it comes with higher latency. This release also includes new cache-ehcache functionality that provides a disk cache implementation required for tiered caching. Those interested in trying out this experimental feature should consult the documentation for further details and installation instructions.
Ease of use
This release includes updates that reflect the ongoing work to improve OpenSearch’s ease of use in the areas of navigation, data discovery, and data exploration.
Access multiple data sources with consistent navigation and discovery tools
Support for multiple data sources in OpenSearch Dashboards lets you manage data sources across OpenSearch clusters and combine visualizations into a single dashboard. With this release, OpenSearch extends the multiple data sources functionality across nine external Dashboards plugins, including Index Management, ML Commons, Search Relevance, Anomaly Detection, Maps, Security, Notifications, Trace Analytics, and Query Workbench. Multiple data sources are also enabled for two core plugins: Region Map and the time-series visual builder. New menu components available on the navigation bar or embeddable into the page offer a consistent interface across data sources and dashboards. These updates represent another step toward a unified “dashboards anywhere” user experience for visualizing and extracting insights from different data sources and workstreams.
Increase flexibility for cluster settings configuration (Experimental)
Another addition to OpenSearch’s multiple data sources capabilities comes with the addition of cluster-level dynamic application configuration as an experimental feature. This feature offers users a secure and flexible set of tools for controlling additional cluster settings, such as Content Security Policy (CSP) rules, to help assure a good user experience while maintaining security standards.
Search and ML
OpenSearch 2.14 includes several new additions to OpenSearch’s search and ML toolkit to make ML-powered applications and integrations easier to build.
Integrate any ML model and build solutions faster with API-native ingest
An update to the ML framework allows you to integrate any ML model and use models to enrich data streams through the Ingest API. The model APIs now support user-defined model interfaces—strong typing for model inputs and outputs—for your custom models and AI services. These APIs are powered by AI connectors that can be integrated with any ML model hosting or AI API provider.
Previously, the ML framework was limited to integrations with text embedding models, with an embedding ingest processor to generate vector embeddings through our Ingest API. This release introduces an ML inference processor that allows you to perform inferences on any integrated ML model to enrich your pipeline. Types of models can include name-entity-recognition (NER), optical character recognition (OCR), image metadata extractors (objection classifiers and detectors), multi-modal embeddings, language and personally identifiable information (PII) detectors, and more. These models let you support a plethora of use cases involving automated metadata generation and intelligent document processing—traditionally labor-intensive processes that can be slow, inefficient, and costly to scale. Now you can apply native integrations and abstractions through standardized APIs to easily transition between model providers and build faster.
Use OpenSearch as a semantic cache for LangChain applications
OpenSearch now offers a semantic cache for LangChain applications. The semantic cache uses OpenSearch’s k-NN indexes to cache large language model (LLM) requests and responses, helping users reduce costs by reducing expensive LLM calls. Previously, you could build apps like chatbots on LangChain with the OpenSearch vector store and the retrieval augmented generation (RAG) template. Now you can also use OpenSearch as a semantic cache to cache responses for LLM requests like “how do I use OpenSearch for vector search” so that responses to similar requests, like “instruct me on using OpenSearch as a vector database” can be handled without additional costly LLM calls.
Build neural sparse queries with a vector interface
Released in version 2.11, neural sparse functionality simplifies the work of building semantic search applications by using semantic sparse encoders. Prior to this release, users utilized neural sparse search through a high-level query interface that abstracts away and manages the query-time ML inference pipeline. Users could perform term-based and natural language queries through this interface. With this release, we’ve added a lower-level vector query interface that allows you to run a neural sparse query by providing a sparse vector as a list of weighted tokens as inputs. This gives users the option to manage ML inferencing and pipelining on the client side. With this interface, users generate the sparse vectors as a list of weighted tokens on the client-side, and input this token list in a query to retrieve semantically similar documents.
Filter k-NN results based on maximum distance or vector score
Traditionally, similarity search is designed around finding the k-NN—in other words, the “top k” most similar documents. This release brings an enhanced k-NN query interface that lets you retrieve only results within a certain maximum distance or vector score. This is ideal for use cases in which your goal is to retrieve all the results that are highly or sufficiently similar (for example, >= 0.95), avoiding the possibility of missing highly relevant results because they don’t meet a “top k” threshold.
Build search pipelines with index alias support
A core component of OpenSearch capabilities like hybrid and conversational search, search pipelines allow users to configure a sequence of processors that enrich query requests and results on the server side. A new enhancement lets you use a single search pipeline as a default for multiple indexes and aliases. This gives you the option to use search pipelines with the benefits of index aliases for improved reusability.
Stability, availability, resiliency
The 2.14 release also includes an update to support stability, availability, and resiliency for our distribution artifacts.
New PGP public key available for artifact verification
OpenSearch’s current PGP public key is scheduled to expire on May 12, 2024. To support future verification of artifact signatures, we have updated our key to expire on May 12, 2025. If you wish to verify TAR/ZIP/DEB/RPM artifacts, visit https://opensearch.org/verify-signatures.html to download the new public key. For APT and YUM repositories, the package manager will automatically attempt to retrieve the updated key during the next installation.
Get started with OpenSearch 2.14
You can find the latest version of OpenSearch on our downloads page. There’s more to learn about the new OpenSearch tools in the release notes, documentation release notes, and documentation, and OpenSearch Playground is a great way to dig into the new visualization options. As always, we would appreciate your feedback on this release on our community forum.
OpenSearch is on the road! Our user conference has grown, and the first-ever OpenSearchCon India is coming up soon. We hope you’ll consider joining the OpenSearch community on June 26 in Bengaluru—visit this page to learn more. And the third annual OpenSearchCon North America is officially scheduled for September 24–26 in San Francisco! The Call for Presentations is open now, so get your submissions in soon!
