
















Enhanced multi-vector support for OpenSearch k-NN search with nested fields
OpenSearch 2.12 significantly enhances k-NN indexes that use the HNSW algorithm with Faiss or Lucene engines, boosting result diversity by intelligently handling multi-vector support. OpenSearch has integrated Lucene’s Parent Block Join implementation for the enhancement with the Lucene engine. This improvement ensures better search outcomes by effectively eliminating duplicate vectors from the same document during k-NN searches.
Why is this important?
With the rise of large language models (LLMs), many users are turning to vector databases for indexing, storing, and retrieving information, particularly for building retrieval-augmented generation (RAG) systems. Vector databases rely on text embedding models to convert text to embeddings, preserving semantic information. However, models have limitations on the number of tokens to consider for embedding generation, thus requiring large documents to be chunked and stored as multiple embeddings in a single document. Without multi-vector support, every chunk of the document needs to be treated as a separate entity, which leads to duplication of document metadata across multiple chunks unless the user separates the document and its metadata. This duplication of metadata can result in significant storage and memory overhead. Furthermore, users must independently devise a merging mechanism to ensure that only a single document is retrieved from multiple chunks during search. Multi-vector support simplifies handling large documents, alleviating these challenges.
Understanding previous limitations
There were two limitations in k-NN search with nested fields prior to OpenSearch 2.12.
Fewer results
In previous versions of OpenSearch, when searching for nested k-NN fields with a specified number of nearest neighbors (k value), the search might return fewer than k documents. This occurred because the search operated at the nested field level or chunk level rather than the document level. In the worst-case scenario, it was possible that k neighbors could be the chunks belonging to a single document, returning just one document in the search results. While increasing the k value could result in a greater number of retrieved documents, it introduced unnecessary search overhead.
For example, consider three documents labeled 1, 2, and 3, each containing two vectors in the nested k-NN field. Document 1 contains vectors A and B, document 2 contains vectors C and F, and document 3 contains vectors D and E. Let’s say the two nearest vectors are A and B, both belonging to document 1. When searching for the nested k-NN field, the search returns only document 1, even if the k value is set to 2, as shown in the following image.
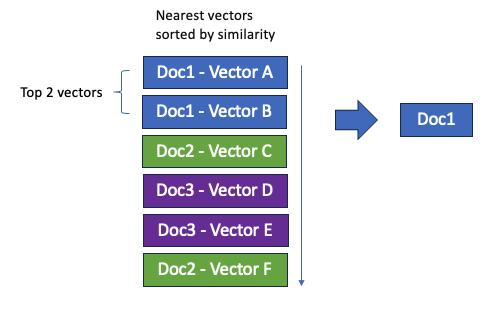
Low recall
Returning fewer results can also lead to low recall. In OpenSearch, an index consists of multiple shards, each containing multiple segments. Search operates at the segment level, with results aggregated at the shard level. After this, the results from all shards are aggregated and returned to the user. Consequently, if a single segment contains all of the top k documents but returns fewer than k documents, the final results will contain k documents but will not represent the true top k documents. This is because the search algorithm operates at the segment level, potentially missing relevant documents from other segments that should have been included in the top k results.
To illustrate this, consider the following example. Suppose there are seven indexed documents, each containing either one or two vectors. Let’s assume that, when searching the nested vector field, the order of vectors from nearest to farthest is as follows: A, B, C, D, E, F, G, H, I, and J. The search occurs at the segment level, and with a k value of 2, only document 1 is returned from segment 1. Consequently, the final aggregated results contain document 1 and document 3, whereas the expected results should include document 1 and document 2, as shown in the following image.
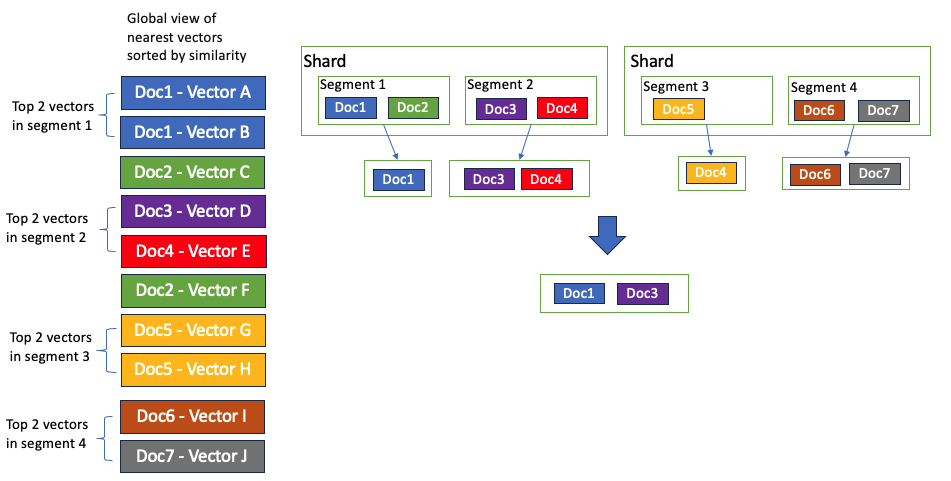
Improvements in OpenSearch 2.12
In version 2.12, OpenSearch uses document and vector mapping data to deduplicate search results. This process occurs when vectors belonging to the same document are already collected in the search queue. During deduplication, OpenSearch keeps only the nearest vector to the query vector for each document. The distance value of the selected vector is then converted back to an OpenSearch search score, ultimately becoming the document’s score.
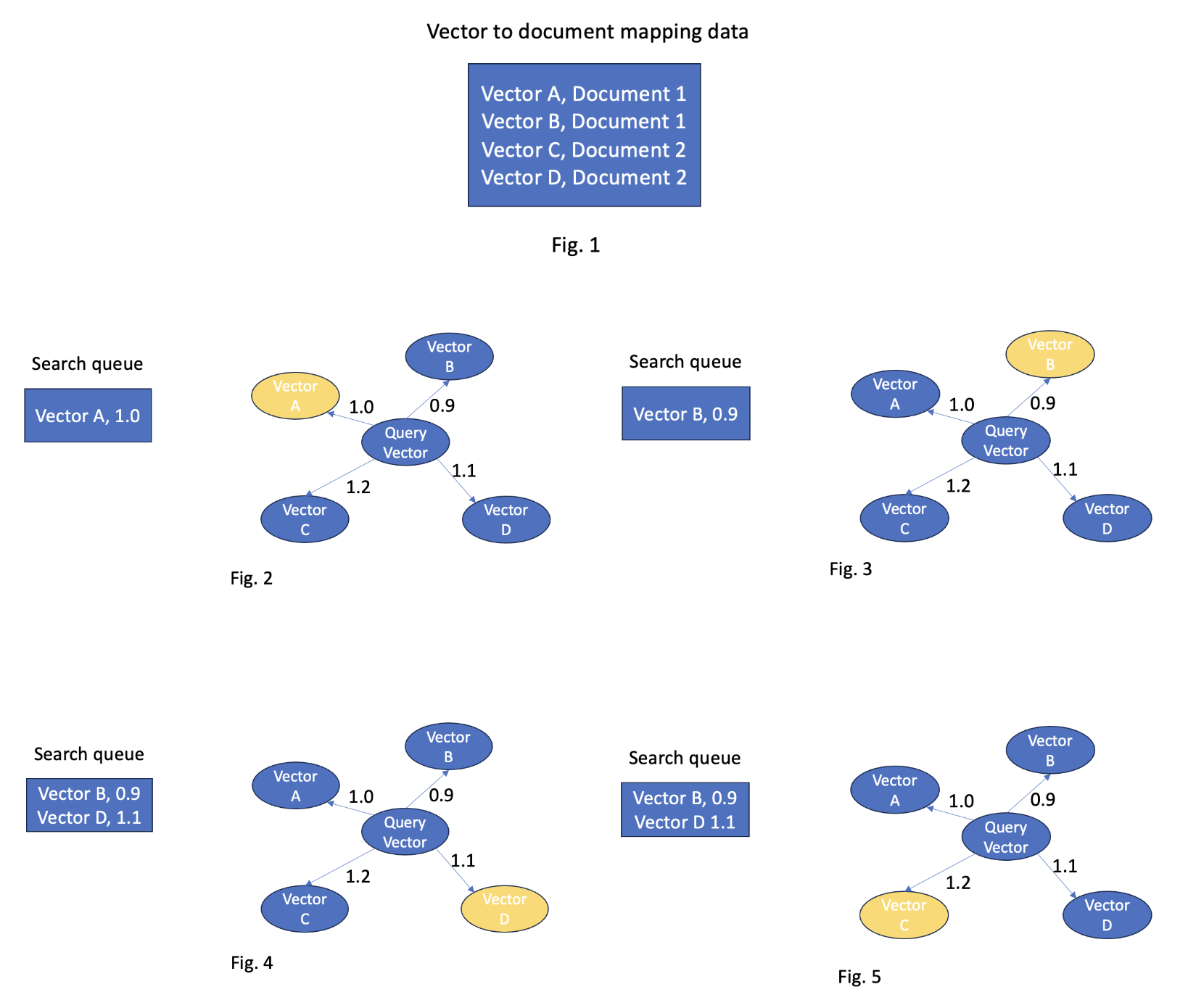
Let’s take a look at an example, presented in the following diagrams. Consider two documents, document 1 and document 2. Document 1 contains vectors A and B, while document 2 contains vectors C and D (Fig. 1). During the search, vector A is found and added to the search queue (Fig. 2). Subsequently, vector B is found. Because both vectors A and B belong to document 1, their distances are compared. The distance between the query vector and vector B is 0.9, which is less than the distance between the query vector and vector A (1.0). As a result, vector A is removed from the search queue, and vector B is added (Fig. 3).
After that, vector D is found. Because vector D belongs to document 2, whose vector is not in the search queue, vector D is added to the queue (Fig. 4). Then vector C is found. Because vector C belongs to document 2, whose vector is already in the search queue, the distances between the query vector and vectors C and D are compared. The distance between the query vector and vector D (1.1) is less than the distance between the query vector and vector C (1.2), so vector D remains in the search queue (Fig. 5).
Both document 1 and document 2 are returned, and their scores are calculated based on the distances between the query vector and the vectors collected in the search queue.
Now, even with a k value of 2, the search returns two documents, regardless of whether the two nearest vectors belong to one or multiple documents. Additionally, this enhancement improves recall because each segment now returns the k nearest documents instead of just the k nearest vectors belonging to the documents.
How to use a nested field to store a multi-vector
Let’s dive into the process of creating a k-NN index with nested fields and conducting searches on it.
First, create a k-NN index by setting the knn value to true in the index settings. Additionally, set the type to knn_vector within the nested field. All other parameters for the knn_vector remain the same as those for a regular knn_vector type:
PUT my-knn-index
{
"settings": {
"index": {
"knn": true
}
},
"mappings": {
"properties": {
"my_vectors": {
"type": "nested",
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 2,
"method": {
"name": "hnsw",
"space_type": "l2",
"engine": "faiss"
}
}
}
}
}
}
}
Next, insert your data. The number of data entries within a nested field is not fixed; you can index a different number of nested field items for each document. For instance, in this example, document 1 contains three nested field items and document 2 contains two nested field items:
PUT _bulk?refresh=true
{ "index": { "_index": "my-knn-index", "_id": "1" } }
{"my_vectors":[{"my_vector":[1,1]},{"my_vector":[2,2]},{"my_vector":[3,3]}]}
{ "index": { "_index": "my-knn-index", "_id": "2" } }
{"my_vectors":[{"my_vector":[10,10]},{"my_vector":[20,20]}]}
When you search the data, note that the query structure differs slightly from a regular k-NN search. Wrap your query in a nested query with the specified path. Additionally, your field name should specify both the nested field name and the knn_vector field name, separated by a dot (in the following example, my_vectors.my_vector):
GET my-knn-index/_search
{
"query": {
"nested": {
"path": "my_vectors",
"query": {
"knn": {
"my_vectors.my_vector": {
"vector": [1,1],
"k": 2
}
}
}
}
}
}
When specifying a k value of 2, you’ll retrieve two documents instead of one, even if the three nearest vectors belong to document 1:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "my-knn-index",
"_id": "1",
"_score": 1.0,
"_source": {
"my_vectors": [
{
"my_vector": [
1,
1
]
},
{
"my_vector": [
2,
2
]
},
{
"my_vector": [
3,
3
]
}
]
}
},
{
"_index": "my-knn-index",
"_id": "2",
"_score": 0.006134969,
"_source": {
"my_vectors": [
{
"my_vector": [
10,
10
]
},
{
"my_vector": [
20,
20
]
}
]
}
}
]
}
}
Summary
In OpenSearch 2.12, you can now obtain more accurate search results from a k-NN index, even when multiple nearest vectors belong to just a few documents. This represents a significant stride toward establishing OpenSearch as a competitive vector database. Additional enhancements that will support multi-vector functionality, such as inner hit support[#1447] and automatic chunking[#548], are currently in the pipeline. If you want to see these features implemented, please upvote the corresponding GitHub issue. As always, feel free to submit new issues for any other ideas or requests regarding the OpenSearch k-NN functionality in the k-NN repository.


