
















Introducing concurrent segment search in OpenSearch
OpenSearch is a scalable, flexible, and extensible open-source search and analytics engine. It is built on top of Apache Lucene and uses its powerful capabilities to ingest user data and serve search requests with latency in milliseconds.
Users are always looking for ways to improve their search performance. For latency-sensitive use cases, users are fine with scaling their clusters for improved latency at the cost of adding more resources. There are also users who already have available resources in their cluster and are still unable to improve the latency of their search requests. Apache Lucene constantly improves the search algorithms and heuristics, and OpenSearch incorporates those improvements into its engine. Some of them are straightforward optimizations, but others require significant system redesign. Concurrent segment search is a feature that requires non-trivial changes but improves search latency across a variety of workload types.
Background
Before digging into concurrent search, let’s briefly talk about how OpenSearch stores indexes and handles search requests. OpenSearch is a distributed system, usually deployed as a cluster of nodes. Each cluster has one or more data nodes where the indexes are stored. Each index is split into smaller chunks called shards, which are scattered across data nodes. In turn, each shard is an Apache Lucene index, which is composed of segments, each containing a subset of indexed documents, as shown in the following diagram.
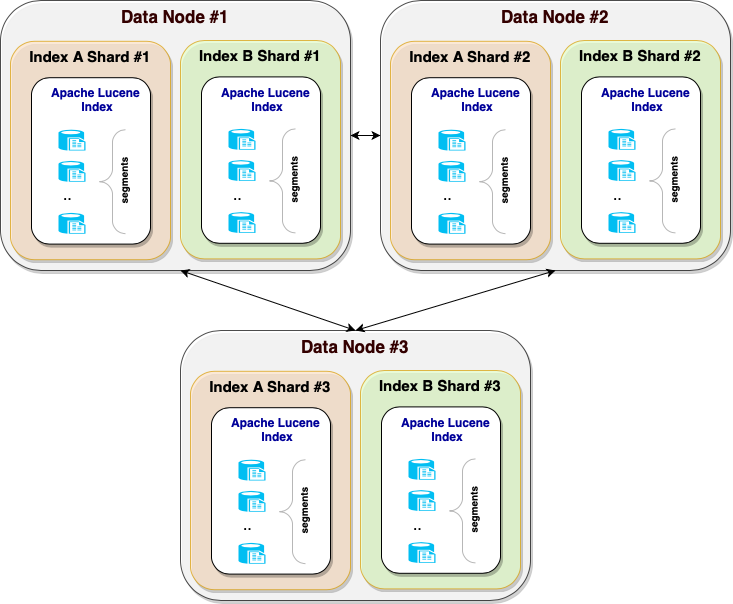
The sharding technique allows OpenSearch to scale to massive amounts of data. However, efficiently servicing search queries becomes a challenge.
Scatter/gather mechanism
OpenSearch follows a scatter/gather mechanism when executing search requests and returning responses to the client. When a search
request lands on a cluster node, that node acts as a coordinator for the request. The coordinator determines which indexes and shards will be used to serve a search request and then orchestrates different phases of the search request, such as can_match, dfs, query, and fetch. Depending on the search request type, one or more phases will be executed. For example, for a request where size is 0, the fetch phase is omitted and only the query phase is executed.
Query phase
Let’s now focus on the query phase, where the actual search request processing and document collection happen. After identifying the shards, the coordinator node sends an internal request (let’s call it a shard search request) to each of the shards in batches (limiting the number of shard search requests sent to each node in parallel). When each shard responds back with its set of documents, the coordinator merges the responses and sends the final response back to the client. The following diagram illustrates the communication between the coordinator node and data nodes during the query phase.
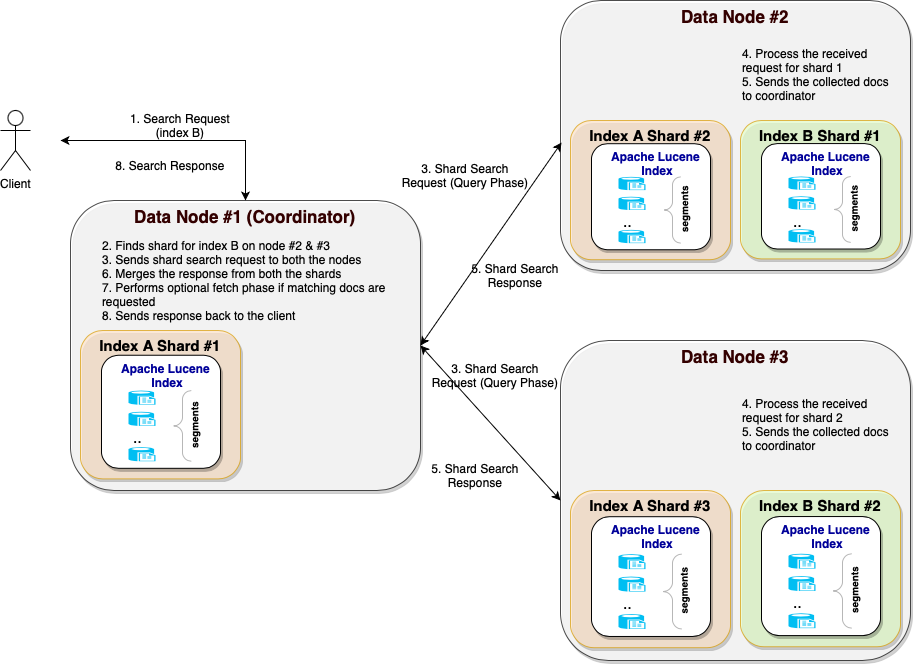
Query phase workflow
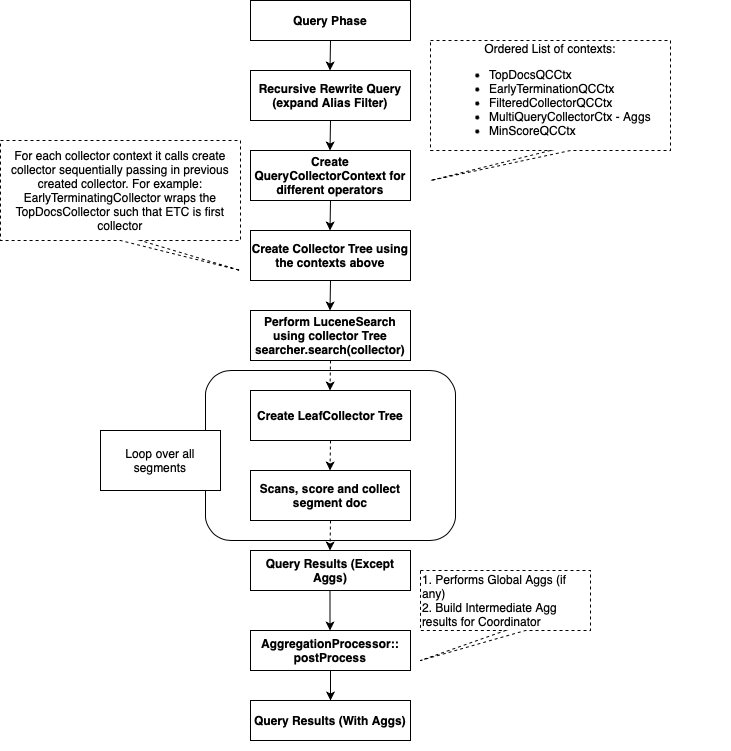
When a shard receives a search request, it tries to rewrite the query (as needed), creating internal objects such as a query, weights, and a collector tree needed to process the request using Lucene. These represent the various clauses or operations, like filters, terminate_after, or aggregations, defined in the body of the search request. Once the setup is complete, Lucene’s search API is called to perform the search on all the segments of the shard sequentially.
For each segment, Lucene applies the filter and Boolean clauses provided in the query in order to identify and score matching documents. Then the matched documents are passed through the collector tree to collect the matched document IDs. For example, TopDocsCollector collects the top matching documents, while different BucketCollector objects aggregate matching document values depending on the aggregation type.
Once all matching documents are collected, OpenSearch performs post-processing to create the final shard-level results. For example, aggregations perform post-processing where an internal representation for each aggregation result (InternalAggregation) is created and sent back to the coordinator node. The coordinator node accumulates all aggregation results across shards and performs the reduce operation to create the final aggregation output that is sent back in the search response. The following diagram illustrates the non-concurrent query phase workflow.
Concurrent segment search
In the early days of Apache Lucene, the index searcher was enhanced with a new experimental capability to traverse segments concurrently. In theory, concurrent segment search offers noticeable improvements in search latency by using multiple threads to search segments.
The first implementation of concurrent segment traversal was included in OpenSearch 2.0.0 as a sandbox plugin (see this PR). Later we decided to close all the gaps—adding support for aggregations, profile API enhancement, and stats—and move the feature toward GA readiness (see the corresponding GitHub issue). So why is concurrent segment search a game changer for certain workloads?
How concurrent search works
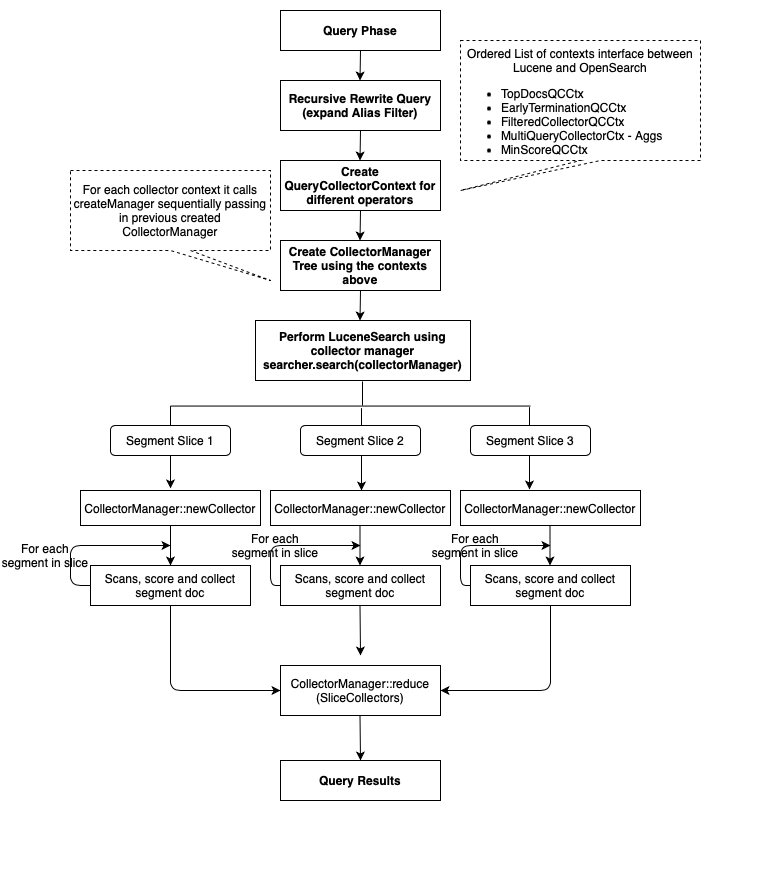
Concurrent segment search uses the previously described Lucene capability to process the shard search request during the query phase. There is no change to the flow between the coordinator node and the shards. For shard search requests, instead of searching and collecting the matched documents one segment at a time, concurrent segment search performs the collection across segments concurrently. In the concurrent search model, all the segments for a shard are divided into multiple work units called slices. To compute the slice count for each request, by default, OpenSearch uses the Lucene heuristic, which allows up to a maximum of 250,000 documents or 5 segments per slice, whichever is met first. Each slice will have one or more segments assigned to it, and each shard search request will have one or more slices created for it. Each slice is executed on a separate thread in the provided index_searcher thread pool, which is shared across all shard search requests. Once all the slices complete their execution, each slice performs a reduction on the collected results to create the final shard-level result to be sent to the coordinator node.
CollectorManager
To achieve this parallel execution model, Apache Lucene applied a scatter/gather pattern and introduced the CollectorManager interface, which provides two methods: newCollector and reduce. For each shard search request, OpenSearch creates a CollectorManager tree (set up with a concurrent search flow) instead of a Collector tree and passes this CollectorManager tree to the Apache Lucene Search API.
Depending on the computed slice count, Apache Lucene creates a Collector tree using CollectorManager::newCollector for each of the slices. Once all of the slice execution is completed, Lucene calls CollectorManager::reduce to reduce the results collected across Collector instances of each slice. This means that each operation supported in Apache Lucene or OpenSearch that needs to support the concurrent model must have a corresponding CollectorManager interface implementation, which can create the corresponding thread-safe Collector tree. For native Lucene collectors, CollectorManager implementations are supported out of the box. Collectors implemented in OpenSearch need to implement CollectorManager (for example, for MinimumCollectorManager and for handling all aggregations, we implemented AggregationCollectorManager). The following diagram illustrates the concurrent query phase workflow.
Concurrent search with aggregations
One of the challenges of aggregation support is that OpenSearch supports nearly 50 different aggregation collectors. To support concurrent search, we explored different options (see this GitHub issue). We were looking for a mechanism that could support the reduce operation on different aggregation types in a generic way instead of handling it for each aggregation collector separately. Following that tenet, we realized that aggregation reduction is currently performed on the results across shards on the coordinator node, so we can apply a similar mechanism to the slice-level reduction on the shards. Thus, when concurrent search is enabled, for search requests that include an aggregation operation, a reduce operation will occur on each shard for the results across slices. Then another reduce operation will occur on the coordinator node to collect results across shards.
Performance results
Currently, this feature is launched as experimental and is not recommended for use in a production environment. We are working on resolving all the issues found along the way to ensure that the feature is stable for production environments. You can track the status of the feature in the concurrent search section of the project board. With the current functionality in place, we collected preliminary benchmark numbers using the OpenSearch Benchmark nyc_taxis workload. The following sections summarize these benchmarking results.
Cluster setup 1
- Instance type: r5.2xlarge
- Node count: 1
- Shard count: 1
- Search client count: 1
Latency comparison (p90)
| Workload operation | CS disabled (in ms) |
CS enabled (Lucene default slices) (in ms) |
% improvement (positive is better) | CS enabled (fixed slice count=4) (in ms) |
% improvement (positive is better) |
|---|---|---|---|---|---|
| default | 4.4 | 4.6 | −5% | 5 | −14% |
| range | 234 | 81 | +65% | 91 | +61% |
| date_histogram_agg | 582 | 267 | +54% | 278 | +52% |
| distance_amount_agg | 15348 | 4022 | +73% | 4293 | +72% |
| autohisto_agg | 589 | 260 | +55% | 273 | +53% |
Average CPU utilization
| CS disabled | CS enabled (Lucene default slices) | CS enabled (fixed slice count=4) |
|---|---|---|
| 12% | 65% | 43% |
Cluster setup 2
- Instance type: r5.8xlarge
- Node count: 1
- Shard count: 1
- Search client count: 1
Latency comparison (p90)
| Workload operation | CS disabled (in ms) |
CS enabled (Lucene default slices) (in ms) |
% improvement (positive is better) | CS enabled (fixed slice count=4) (in ms) |
% improvement (positive is better) |
|---|---|---|---|---|---|
| default | 4.25 | 4.7 | −11% | 4.1 | +3% |
| range | 227 | 91 | +59% | 74 | +67% |
| date_histogram_agg | 558 | 271 | +51% | 255 | +54% |
| distance_amount_agg | 12894 | 3334 | +74% | 3790 | +70% |
| autohisto_agg | 537 | 286 | +46% | 278 | +48% |
Average CPU utilization
| CS disabled | CS enabled (Lucene default slices) | CS enabled (fixed slice count=4) |
|---|---|---|
| 3% | 14% | 11% |
These are just the initial results, and we plan to run other scenarios to measure the effect of concurrent segment search on performance. We will follow up with a blog post providing benchmarking results from additional real-world scenarios, like multiple clients and multiple shards per node, and share the observations with you. This meta issue is tracking the benchmarking plan, including different setups and scenarios. If you think there are other scenarios worth pursuing, leave your feedback in this issue. You can also contribute by running these scenarios or other custom workloads and sharing the results with us.
Enabling concurrent search
To enable and use concurrent segment search in your cluster, follow the instructions in the concurrent search documentation.
Limitations
There are a few areas that do not yet support concurrent search (for example, ParentJoinAggregation). To learn more, refer to the limitations section of the documentation.
Wrapping up
We are excited to support concurrent segment search in OpenSearch, and we highly encourage you to try the feature in a non-production environment and provide feedback about any gaps or issues we can help fix to make the feature more robust and user friendly. You can track the progress of this feature on this project board.

