
















The power of star-tree indexes: Supercharging OpenSearch aggregations
Aggregations in OpenSearch play a critical role in enabling real-time data analysis and visualization. They are extensively used in OpenSearch Dashboards to create interactive charts and dashboards, providing insights into large volumes of data. But as your data grows, aggregation performance can suffer. That’s where the new star-tree index comes in.
The star-tree index feature, introduced in OpenSearch 2.18, precomputes aggregations during indexing. By doing so, it significantly reduces query latency, especially for large datasets and complex aggregations. Whether you’re running dashboards on log data or computing metrics for millions of records, a star-tree index can help you run queries faster and more predictably, without the need to change your queries.
In this blog post, you’ll learn what a star-tree index is, how it works, and how you can use it to accelerate your aggregations.
Aggregations in OpenSearch
OpenSearch provides several types of aggregations, such as the following:
- Metric aggregations: Compute metrics, such as sum, min, max, or average, on numeric fields.
- Bucket aggregations: Group query results based on defined criteria, for example, by time intervals using date histograms.
However, compared to standard queries, aggregations can introduce performance challenges:
- Scalability: Query latency increases with the number of matching documents.
- Resource consumption: Aggregations require more CPU, memory, and disk usage.
For example, suppose that you want to analyze application logs by computing a metric aggregation, such as the average or sum, grouped by HTTP status code.
The following table compares query latency when aggregating on both a high-frequency and low-frequency status code.
| Query | Number of documents | Latency, milliseconds |
|---|---|---|
Metric aggregation for status = 200 |
200,000,000 | 4,200 |
Metric aggregation for status = 400 |
3,000 | 5 |
In this case, status code 200 (OK) appears very frequently in the logs, while status code 400 (Bad Request) is relatively rare. Aggregations on high-frequency values like 200 require scanning a much larger number of documents, leading to significantly higher latency. In contrast, aggregations on low-frequency values like 400 involve fewer documents and complete much faster.
The star-tree index feature is designed to reduce this latency, even at scale.
What is a star-tree index?
The star-tree index feature, inspired by Apache Pinot, is OpenSearch’s first multi-field index designed to accelerate aggregations. During indexing, a star-tree index precomputes aggregations for the configured metrics across all combinations of the defined dimensions.
The following image illustrates the high-level architecture of a star-tree index.
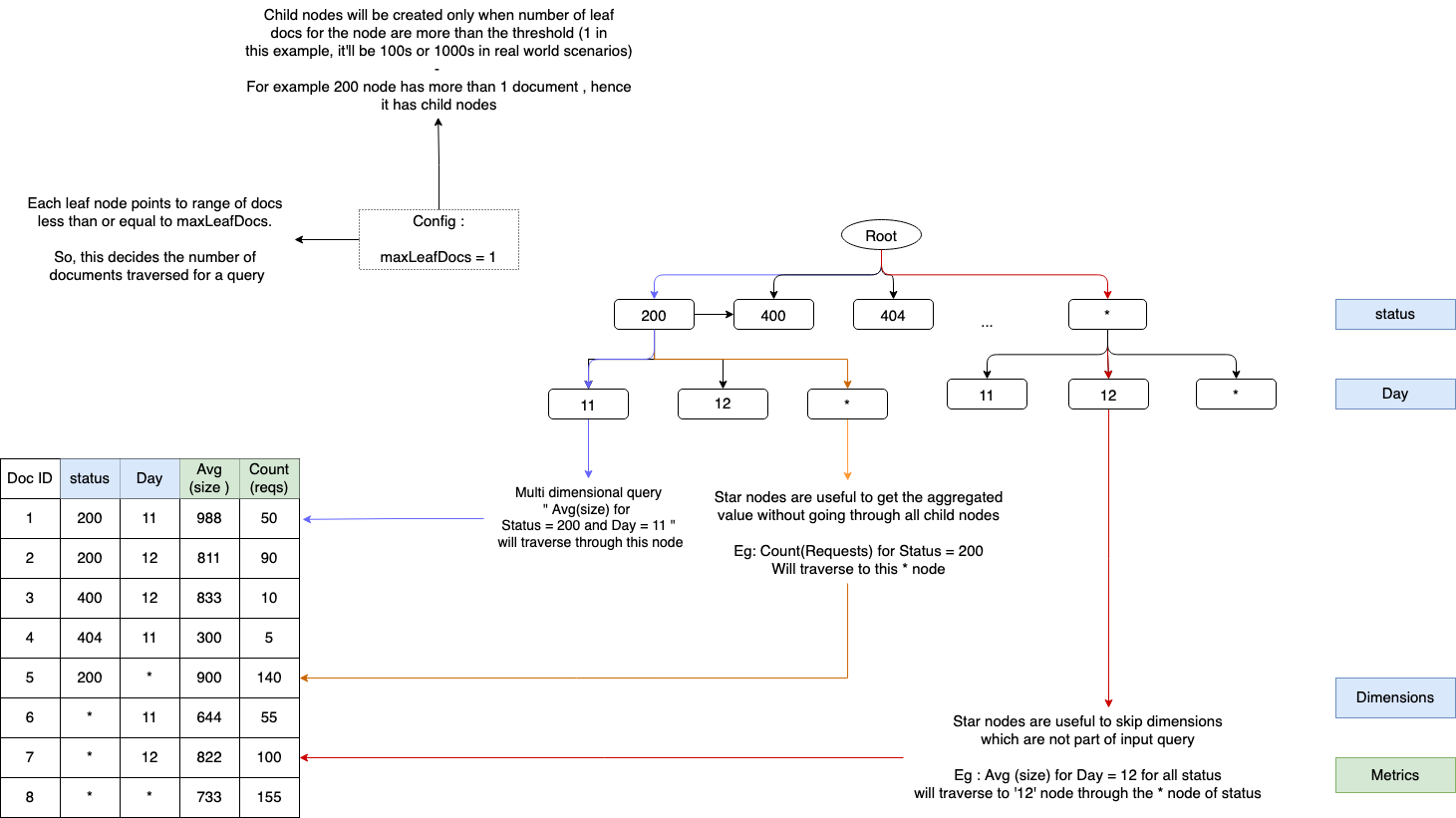
The tree is structured hierarchically based on dimension values, such as status and Day. Each path from the root node to a leaf represents a unique combination of dimension values. Leaf nodes contain aggregated metrics, such as Avg(size) and Count(reqs), for the documents that match that dimension combination. Star nodes (*) are used to represent aggregated values across all values of a particular dimension, allowing queries to skip unnecessary branches. Child nodes are only created if the number of documents exceeds a configurable threshold (maxLeafDocs).
The example in the image shows how queries traverse the tree: a query for average size where status = 200 and Day = 11 follows a specific path (depicted by blue arrows), while a query for average size on Day = 12 (regardless of status) uses a star node to skip the status dimension entirely.
Internally, a star-tree index consists of the following components:
- A star tree that organizes unique dimension values into tree nodes for efficient traversal.
- Columnar doc values that store preaggregated results for the configured dimensions.
For additional technical details, see Star-tree index structure.
Benefits of using a star-tree index
The star-tree index feature offers the following advantages that make it well suited for high-performance analytics at scale.
Predictable latency
Traditionally, aggregation query latency in OpenSearch increases with the number of matching documents. A star-tree index provides faster and more predictable query latency by precomputing aggregation results, as shown in the following table.
| Query | Number of documents | Plain query latency | Star-tree query latency |
|---|---|---|---|
| Avg (duration) for status = 200 | 200 million | 4.2 seconds | 6.3 milliseconds |
| Avg (duration) for status = 400 | 3,000 | 5 milliseconds | 6.5 milliseconds |
Multi-aggregation support
Traditionally, when running queries that involve multiple aggregations on different fields, each field for each aggregation is processed separately, increasing latency. In contrast, a star-tree index offers native multi-field support, making it significantly more efficient in these scenarios. A star-tree index preprocesses queries that span multiple aggregations, eliminating the need for repeated star-tree traversals and thereby improving overall performance.
Improved throughput for complex aggregations
For resource-intensive operations like date histograms with sub-aggregations on large datasets, a star-tree index can significantly reduce latency and increase throughput, as shown in the following table.
| Query | Number of documents | Traditional query latency | Star-tree query latency (N = 10,000) | Traditional query throughput | Star-tree query throughput |
|---|---|---|---|---|---|
| Yearly date histogram on sum of tip amount (passenger count = 1) | 120 million | 13 seconds | 94 milliseconds | 0.08 | 2.01 |
| Yearly date histogram (passenger count = 1–2) | 140 million | 15 seconds | 114 milliseconds | 0.07 | 2.01 |
| Yearly date histogram (passenger count = 1–5) | 160 million | 17 seconds | 160 milliseconds | 0.06 | 2.01 |
Configurability
A star-tree index includes various configuration options that balance storage overhead and query performance. For example, the max_leaf_docs parameter controls how many documents are included in each star-tree leaf. A higher max_leaf_docs value leads to better storage efficiency but increases query latency.
The following table demonstrates the performance difference between traditional queries and star-tree queries with different max_leaf_docs values (N).
| Query | Number of documents | Traditional query latency | Star-tree query latency (N = 100) | Star-tree latency (N = 10,000) |
|---|---|---|---|---|
Metric aggregation for status = 200 |
200 million | 4.2 seconds | 2.5 milliseconds | 6.3 milliseconds |
Metric aggregation for status = 400 |
3,000 | 5 milliseconds | 2.7 milliseconds | 8.5 milliseconds |
Real-time compatibility
While features such as index rollups or transforms offer preaggregated views, they do not operate on real-time data and can degrade indexing performance. In contrast, a star-tree index operates in real time with minimal indexing overhead. Queries require no changes—the engine automatically detects and routes eligible queries to the star-tree index.
Limitations
While the star-tree index feature offers substantial performance benefits, it currently has the following limitations:
- A star-tree index is currently suitable only for immutable datasets. Changes to documents (updates or deletions) are not reflected in the star-tree index.
- A star-tree index is created during refresh/flush/merge operations, which can impact write throughput. Benchmark data will be published soon.
- Once a star tree has been created for an index, it cannot be removed from that index. If you need to disable star-tree functionality, you must reindex all data into a new index without the star-tree mapping configuration. However, you can search the index using traditional rather than star-tree search by setting
indices.composite_index.star_tree.enabledtofalse.
For more information, see Limitations.
How to use a star-tree index
To use a star-tree index, define a star-tree mapping during index creation. The mapping must reflect the dimensions and metrics for the aggregations you want to optimize.
When using your star-tree index, note the following details:
- No changes are required to the query syntax or parameters.
- As of OpenSearch 2.19, only certain aggregation types are supported.
- OpenSearch automatically identifies and optimizes eligible queries using a star-tree index in real time.
- Once configured during index creation, a star-tree index requires no additional maintenance or modifications.
Conclusion
The star-tree index feature significantly improves aggregation performance in OpenSearch. It delivers consistent, low-latency results, even at scale, and requires no query-side changes.
In the future, we’re planning to support additional aggregation and query types, including Boolean queries, date range queries, nested aggregations, and terms aggregations. As adoption grows, the star-tree index feature is poised to become a key component of real-time analytics in OpenSearch. To track this feature’s progress, see this issue.



