
















Do more with less: Save up to 3x on storage with derived vector source
If you’re working with modern applications, from semantic search to recommendation systems, you’re likely implementing vector search. While you might focus on the accuracy and speed of vector similarity searches, you may be overlooking a critical aspect: how these vectors are actually stored and managed within the system. To ensure efficient implementation, you need to understand how OpenSearch handles vector data behind the scenes. In this post, we’ll dive deep into OpenSearch’s vector storage mechanisms and introduce derived source for vectors—a new feature that can significantly reduce your storage costs and improve performance.
How vector data is stored in OpenSearch
When you upload a JSON document to an OpenSearch cluster, the system starts an indexing process—a crucial step that transforms raw data into optimized structures that make search fast and efficient. For example, if the document contains vector data, OpenSearch builds Hierarchical Navigable Small World (HNSW) graphs, depicted in the following image. These specialized data structures power approximate nearest neighbor (ANN) search, allowing for quick and accurate similarity searches across large datasets.
The indexing process often increases the size of the data stored in the cluster compared to the size of the data originally ingested. That’s because OpenSearch prepares the data for different types of search and analytics operations, each requiring its own optimized structure. For example, full-text search relies on inverted indexes, while fast streaming or aggregation over text fields might use a columnar store. To support these diverse needs, the system may store multiple representations of the same data, shown in the following image, resulting in increased storage usage.
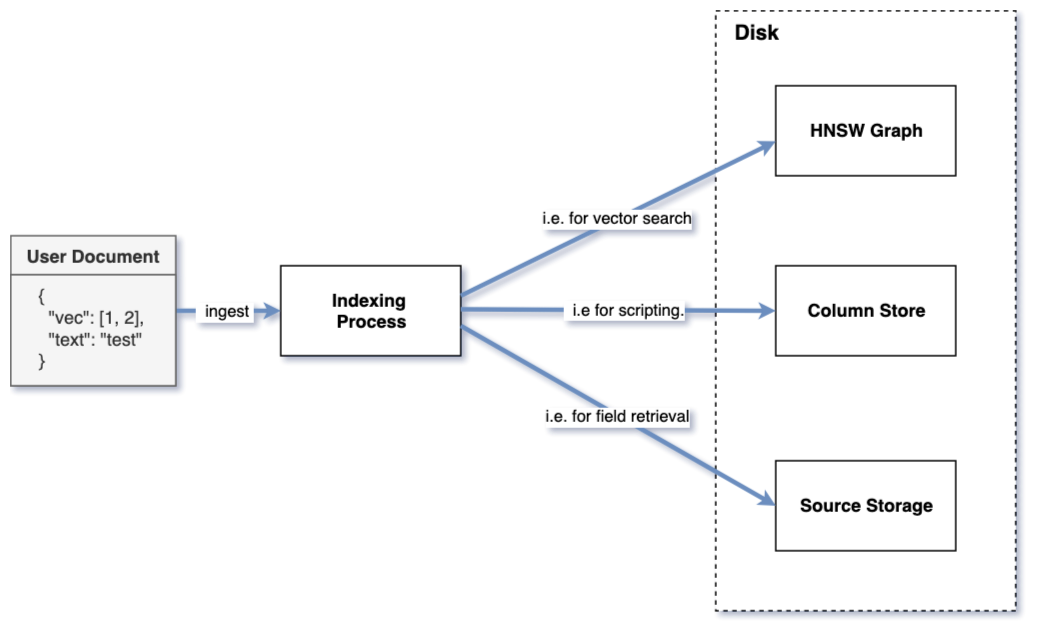
When it comes to vector data, OpenSearch typically stores it in two or three different places, each serving a specific purpose:
- HNSW graph – This is the core structure used for ANN search, enabling fast and efficient vector similarity lookups. Some engines store the actual vector data within this graph, while others keep it separate.
- Vector values – Stored in a columnar format, these raw vectors are often used during the final ranking phase of a search or for exact calculations.
_sourcefield – This field contains the original ingested JSON document, preserving the full context and metadata of the data for retrieval or reindexing.
To better understand how vector data impacts storage, we conducted experiments using a test dataset of 10K 128-dimensional vectors. The measured size of different storage components in OpenSearch is shown in the following image.
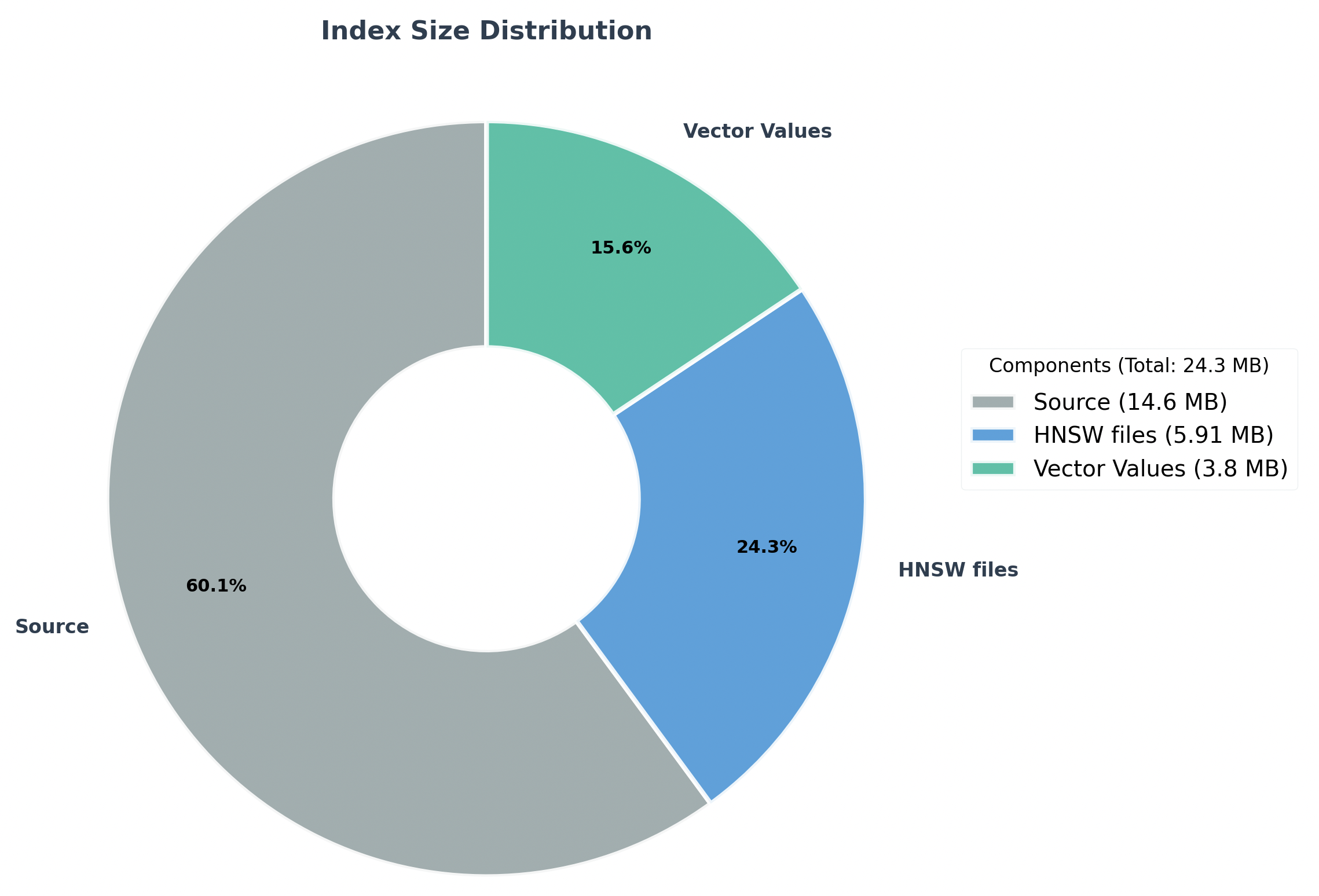
Surprisingly, the _source field accounted for more than half of the index storage. In addition to increasing the index size, storing the _source can hurt performance during indexing, merging, recovery, and even search.
Let’s take a closer look at the purpose of the _source field.
The _source field and vector search
The _source field in OpenSearch serves two key purposes:
-
It stores the original document content and is used to return user-facing fields in search results. For example, if you’re indexing a poetry book, fields like the poem text, title, and author are typically retrieved from the
_sourcefield, unless configured otherwise. -
It enables reindexing and recovery operations. The
_sourceholds the original data needed for updates, rebuilding indexes with new settings (using the Reindex API), or recovery processes such as translog replay.
In Lucene, the _source is implemented as a stored field—a structure designed for retrieving data, not for searching it.
With vector search, you usually don’t need to retrieve the vector itself: a list of floating-point numbers doesn’t convey much meaning to a typical user. For example, if you’re searching for a romantic poem, you don’t care how the poem is semantically represented—you just want the right text, fast.
Vector fields are very large, and including them in responses adds noise to the response and slows down search requests. In production, we typically recommend excluding vector fields from the returned _source to improve performance:
POST /my_index/_search
{
"_source": {
"excludes": ["vector-field"]
},
"query": {
"knn": {
"vector-field": {
"vector": [],
"k": 10
}
}
}
}
If you’re not already doing this, give it a try; you’ll likely see noticeable performance improvements.
For even greater performance gains, you can remove the vector from _source storage altogether. This reduces the overall index size, which in turn leads to smaller shard sizes. Smaller shards can be more quickly relocated between nodes, helping your cluster recover more quickly and reliably during events like node restarts or rebalancing. Additionally, reading less data from disk reduces memory usage, which improves page cache efficiency and can lead to lower search latency.
However, disabling _source storage entirely means losing important functionality, such as the ability to update documents, reindex data, or recover from failures. For many use cases, this trade-off isn’t practical.
The best of both worlds: Derived source
If you’re already storing vectors in the vector values file, you might wonder: Can’t OpenSearch just retrieve the vectors from the file when needed instead of also storing them in _source? As of OpenSearch 3.0, the answer is yes.
Designed for vector indexes, derived source allows OpenSearch to transparently pull vectors from the vector values file when needed without requiring any changes on your part.
Here’s how it works: when indexing a document, OpenSearch replaces the large vector in the _source with a single-byte placeholder before writing it to disk. Then, when reading the _source, if the vector is needed, OpenSearch reads it from the vector values file and inserts it back into the document. This process is depicted in the following diagram.
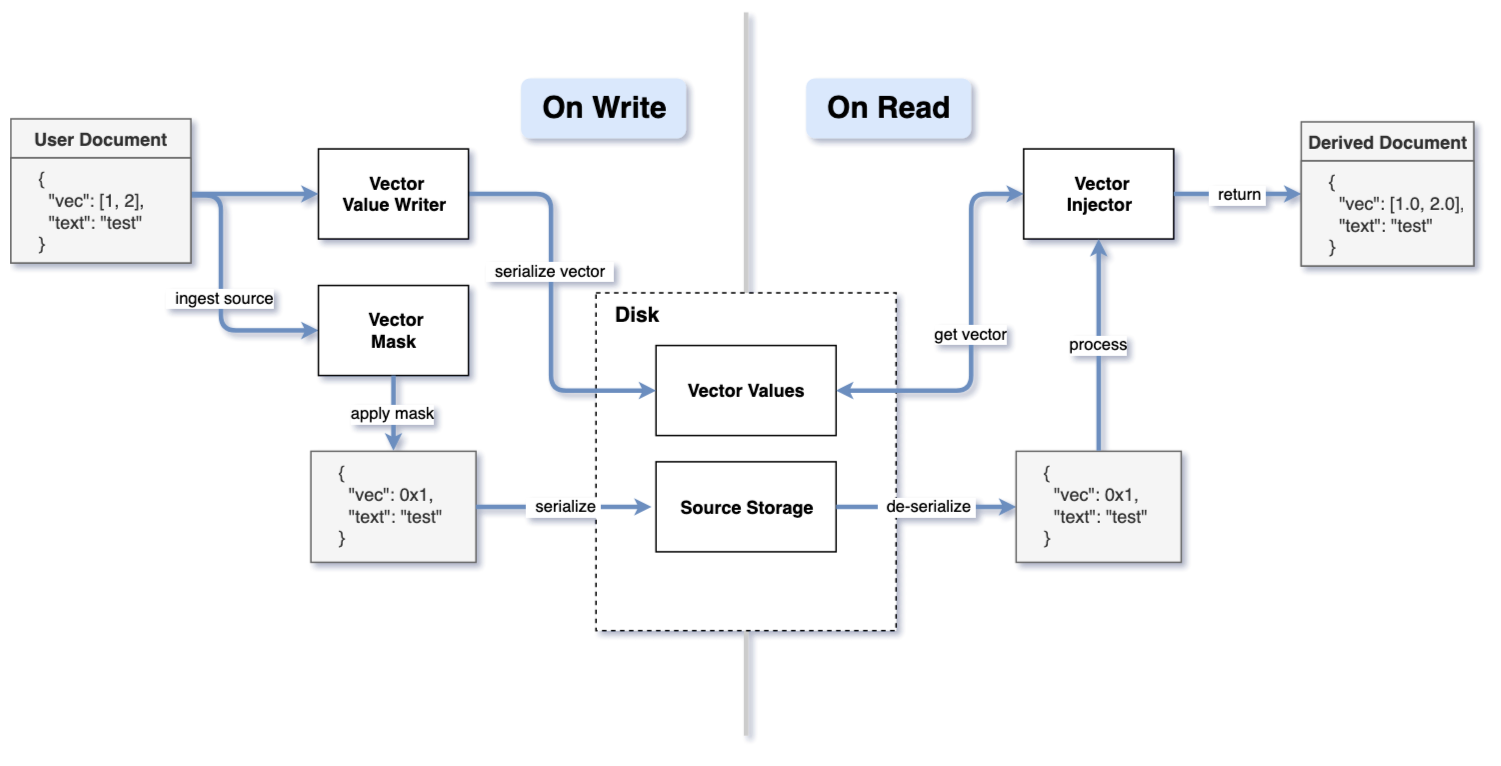
From your perspective, deriving the source is completely transparent. You can enable or disable it using an index setting, and OpenSearch handles the rest behind the scenes. To enable derived source, use the following request and set index.knn to true:
PUT /my_index
{
"settings" : {
"index.knn": true,
"index.knn.derived_source.enabled" : true # Defaults to true
},
"mappings": {
<Index fields>
}
}
Derived source is enabled by default for vector indexes created using OpenSearch 3.0.0 or later.
Performance benchmarks
With this change, our nightly benchmarks showed several notable performance improvements. Most significantly, storage usage dropped by 3x, as shown in the following graph.

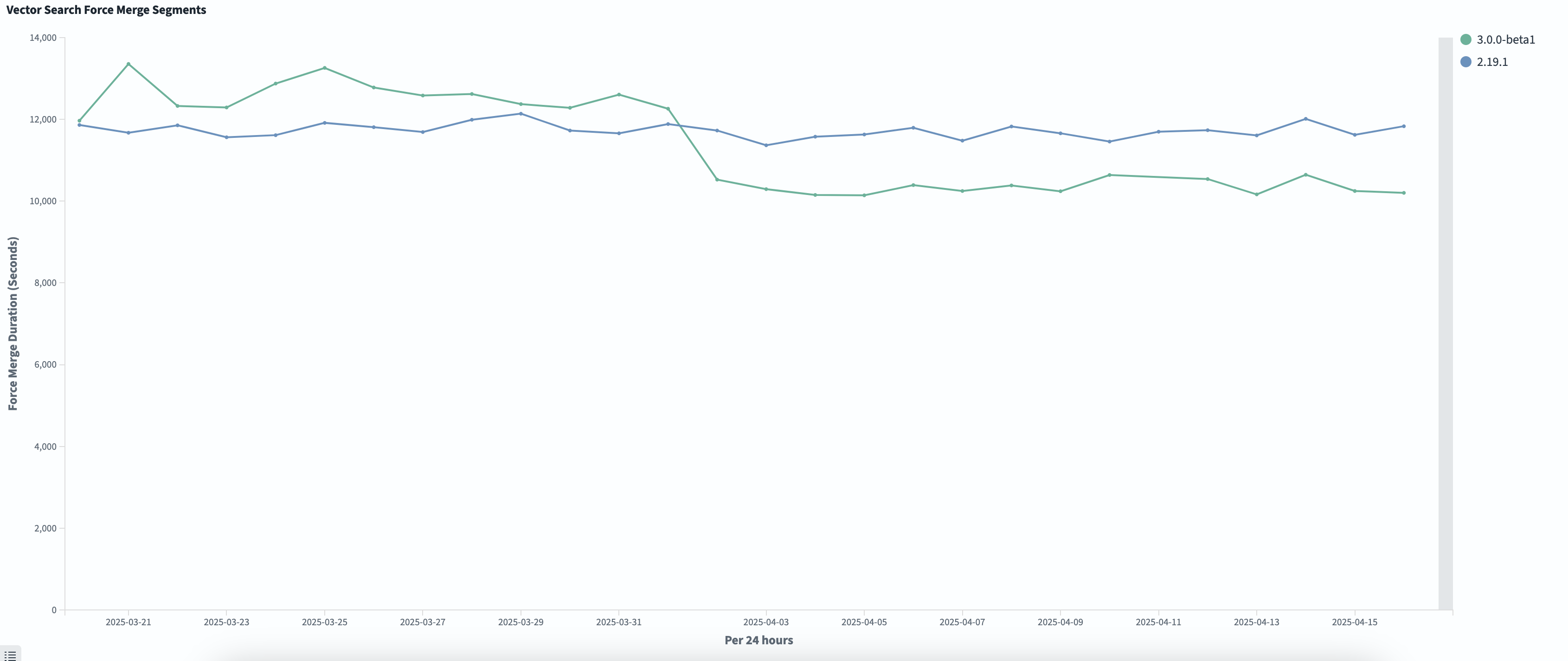
Force merge times also improved, decreasing by about 10%, as shown in the following graph. This decrease is likely caused by the reduced amount of data that needs to be copied and rewritten when creating new segments.
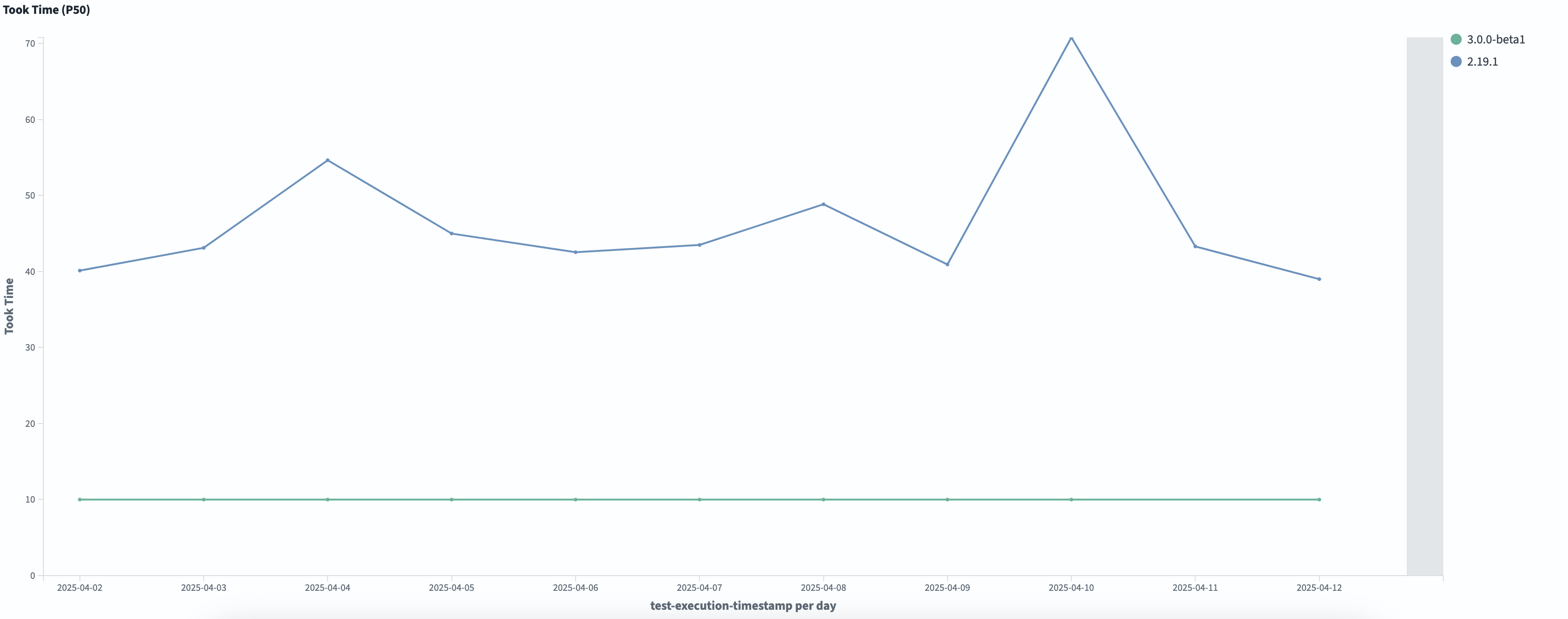
Perhaps most surprisingly, we saw a 90% reduction in search latency when using the Lucene engine, as shown in the following graph. One possible explanation is a cold start effect: during merges, unnecessary vector data is loaded into the page cache and later evicted, only to be reloaded when it is actually needed during search.
These improvements all stem from reducing the amount of data stored and read from disk. By keeping shards smaller, you reduce I/O overhead during common operations like merges and searches. Thus, working with smaller shard sizes often yields surprising performance improvements.
What’s next?
We’re excited to share that we’re not limiting derived source to just vector fields. Upcoming versions will expand support for derived source to all field types, unlocking even more flexibility when you work with OpenSearch.
Interested in how the feature is progressing or want to get involved? Follow the development of the feature and join the conversation on this GitHub issue.


